تکنیک های داده کاوی که باید بدانید – معرفی ۹ تکنیک کلیدی
مفهوم داده کاوی
دادهکاوی (Data Mining) به فرآیندی گفته میشود که طی آن از حجم عظیمی از دادههای خام و پیچیده، اطلاعات مهم و ارزشمندی استخراج میشود. این اطلاعات به مدیران و فعالان کسبوکار کمک میکند تا در تصمیمگیریهای مهم و استراتژیک خود از آنها بهره ببرند. در واقع، دادهکاوی هنر، علم و روشی است برای کشف الگوهای پنهان در دادههای حجیم و پیچیده.
در منابع مختلف، از اصطلاحات دیگری مانند «استخراج اطلاعات از داده»، «گردآوری اطلاعات»، «تحلیل اطلاعات» و «لایروبی داده» به عنوان مترادفهای دادهکاوی استفاده شده است. هدف تمامی این روشها بررسی دادهها به منظور یافتن اطلاعات ارزشمند و کاربردی است.
در دنیای امروز که حجم دادهها به شدت افزایش یافته است، دادهکاوی تبدیل به یکی از مهمترین ابزارها برای کسبوکارها و سازمانها شده است. متخصصان و نظریهپردازان این حوزه همواره به دنبال روشهای بهتری برای افزایش دقت و کارایی فرآیندهای دادهکاوی هستند. مدیران سازمانها برای رسیدن به اهداف خود و کسب سود بیشتر، به اهمیت استفاده از تکنیکهای دادهکاوی برای تصمیمگیریهای دقیق و به موقع واقف شدهاند.
مزایای دادهکاوی برای کسبوکارها
کمک به درک رفتار مشتری و هوش تجاری: دادهکاوی با کشف روابط و الگوهای پنهان در دادهها به کسبوکارها کمک میکند تا رفتار مشتریان خود را بهتر درک کنند و بهبودهایی در استراتژیهای بازاریابی و فروش ایجاد کنند.
شناسایی دادههای نویزی و ناصحیح: تکنیکهای دادهکاوی قادرند دادههای نویزی (Noise) و ناصحیح را شناسایی کرده و آنها را از دادههای معتبر جدا کنند. این امر باعث میشود که تحلیلها دقیقتر و قابل اعتمادتر باشند.
تصمیمگیریهای بهینه: دادهکاوی به ذینفعان سازمانها کمک میکند تا تصمیمات مهمی را بر اساس روابط مشتریان، بهینهسازی قیمت، تحلیل ریسک، رقابت بازار و سایر عوامل اقتصادی اتخاذ کنند.
پیشبینی دقیق و شناسایی الگوهای پنهان: استفاده مؤثر از تکنیکهای دادهکاوی به پیشبینی دقیق روندها و شناسایی الگوهای پنهان در دادهها منجر میشود. این به کسبوکارها کمک میکند تا بازدهی خود را به طور چشمگیری افزایش دهند.
کشف نقاط ضعف و گلوگاهها: به کارگیری دادهکاوی برای کشف نفوذها و شناسایی نقاط ضعف و گلوگاهها در فرآیندهای عملیاتی میتواند باعث بهبود کارایی سازمانها شود.

انواع تکنیک های داده کاوی
دادهکاوی (Data Mining) فرآیندی است که شامل استفاده از روشهای ریاضی، آماری و علم داده برای استخراج الگوهای پنهان از دادههای خام است. این الگوها به کسبوکارها و تحلیلگران کمک میکنند تا در تصمیمگیریهای مهم خود به نتایج دقیق و مبتنی بر داده دست یابند. در ادامه، فهرستی از تکنیکهای دادهکاوی آورده شده است که در تحلیل دادهها و حل مسائل مختلف کاربرد دارند.
کلیک کنید
- «طبقه بندی» (Classification)
- «خوشه بندی» (Clustering)
- «ردیابی الگوها» (Tracking Patterns)
رگرسیون - «تشخیص دادههای پرت یا تشخیص ناهنجاری» (Outlier Detection or Anomaly Detection)
- «الگوهای متوالی» (Sequential Patterns)
پیشبینی - «قوانین انجمنی» (Association Rules)
- «شبکه عصبی» (Neural Network)
در این مقاله، انواع مختلف تکنیکهای دادهکاوی و کاربردهای آنها بررسی شد. استفاده از این تکنیکها به کسبوکارها کمک میکند تا از دادههای خود بهرهبرداری بهینه کرده و در تصمیمگیریهای استراتژیک خود موفقتر عمل کنند. با انتخاب و بهکارگیری مناسب هر یک از این تکنیکها، سازمانها قادر خواهند بود به بینشهای ارزشمندی دست یابند که منجر به بهبود عملکرد و افزایش بهرهوری میشود.
RapidMiner یک پلتفرم محبوب در علم داده و دادهکاوی است که به تحلیلگران و دانشمندان داده این امکان را میدهد تا با استفاده از ابزارهای پیشرفته خود، دادهها را تحلیل کرده و مدلهای پیچیده بسازند. این پلتفرم در تحلیل دادههای بزرگ و پیچیده بسیار کاربردی است.
تکنیک داده کاوی طبقه بندی
طبقهبندی یکی از تکنیکهای اصلی دادهکاوی است که به فرآیند تقسیم دادهها به دستههای از پیش تعیینشده اشاره دارد. این تکنیک به کسبوکارها کمک میکند تا دادهها را براساس ویژگیهای خاص به گروههای مشابه دستهبندی کنند. برای درک بهتر این تکنیک، فرض کنید قصد دارید کمد لباس خود را مرتب کنید. میتوانید لباسها را بر اساس ویژگیهای مختلف نظیر سبک (اسپرت، رسمی)، رنگ (روشن، تیره) یا فصل (تابستانی، زمستانی) تقسیم کنید. هدف از طبقهبندی در دادهکاوی نیز مشابه همین است: دستهبندی دادهها بر اساس ویژگیهای مشترک برای کمک به تصمیمگیریهای مؤثر.
این تکنیک از دستهبندی به روش یادگیری نظارتشده (Supervised Learning) در یادگیری ماشین تعلق دارد، به این معنا که دادهها و برچسبهای آنها (دستهها) از پیش تعیین شده و الگوریتمها باید آنها را شناسایی و به دستههای مشخص تقسیم کنند.
الگوریتمهای طبقهبندی دادهها
در یادگیری ماشین، الگوریتمهای مختلفی برای طبقهبندی دادهها وجود دارند که بر اساس دادههای آموزشی برچسبدار عمل میکنند. در اینجا به معرفی برخی از الگوریتمهای مهم طبقهبندی میپردازیم:
درخت تصمیم (Decision Tree)
این الگوریتم شبیه به یک درخت است که از شاخهها و گرهها تشکیل شده و هر گره نشاندهنده تصمیمگیری بر اساس ویژگی خاصی است. برای مثال، بانکها از درخت تصمیم برای تعیین اینکه آیا یک مشتری واجد شرایط دریافت وام است یا خیر استفاده میکنند. هر گره نمایانگر یک سوال است که پاسخ به آن منجر به تقسیم دادهها و رسیدن به پیشبینی نهایی میشود.
K نزدیکترین همسایگان (K Nearest Neighbors – KNN)
این الگوریتم دادههای جدید را با مقایسه با k همسایه نزدیک خود طبقهبندی میکند. این روش به طور گسترده برای پیشنهاد محصولات و خدمات به مشتریان بر اساس سابقه خرید و علاقهمندیهای آنها به کار میرود.
ماشین بردار پشتیبان (Support Vector Machine – SVM)
این الگوریتم با استفاده از ابرصفحه در فضای چندبعدی دادهها را جدا میکند. این روش برای طبقهبندی دادههای پیچیده مانند تصاویر و دادههای پزشکی بسیار مفید است.
بیز ساده (Naive Bayes)
این الگوریتم فرض میکند که ویژگیهای دادهها از یکدیگر مستقل هستند و احتمال هر کلاس را بر اساس مقادیر ویژگیها محاسبه میکند. این روش در طبقهبندی متون خبری مانند سیاسی، ورزشی یا سرگرمی بسیار کاربرد دارد.
کاربردهای تکنیک طبقهبندی در دادهکاوی
فیلتر کردن هرزنامهها
یکی از کاربردهای اصلی الگوریتمهای طبقهبندی در فیلتر کردن ایمیلهای هرزنامه است. با تجزیه و تحلیل ویژگیهایی مانند آدرس فرستنده و محتوای ایمیل، سیستم میتواند ایمیلهای مشکوک را به عنوان هرزنامه شناسایی و به پوشه جداگانهای منتقل کند.
دستهبندی مشتریان در بازاریابی
کسبوکارها میتوانند از طبقهبندی برای شناسایی و گروهبندی مشتریان خود استفاده کنند. این امر به آنها کمک میکند تا کمپینهای بازاریابی هدفمند ایجاد کرده و خدمات خود را به مشتریان مناسب ارائه دهند.
تشخیص تقلب در امور مالی
بانکها و موسسات مالی از تکنیکهای طبقهبندی برای شناسایی تراکنشهای مشکوک و تقلبی استفاده میکنند. به عنوان مثال، اگر تراکنشها از الگوی معمول مشتری دور باشند، ممکن است برای بررسی بیشتر علامتگذاری شوند.
افزایش دقت در تشخیصهای پزشکی
الگوریتمهای طبقهبندی میتوانند برای پیشبینی بیماریها با استفاده از دادههای پزشکی بیماران به کار روند. این تکنیک به پزشکان کمک میکند تا تشخیصهای دقیقتری داشته باشند و بیماریهای خطرناک را شناسایی کنند.
تشخیص تصویر در رسانههای اجتماعی
پلتفرمهای رسانههای اجتماعی از الگوریتمهای طبقهبندی برای شناسایی چهرهها و اشیاء در تصاویر استفاده میکنند. به عنوان مثال، هنگام تگ کردن فردی در یک عکس، سیستمها چهرهها را شناسایی کرده و پیشنهاد میدهند که کدام افراد دیگر ممکن است در عکس باشند.

خوشه بندی در داده کاوی
خوشهبندی یکی از تکنیکهای مهم دادهکاوی است که هدف آن گروهبندی دادهها بر اساس شباهتهای دروندادهای است. برخلاف روش طبقهبندی که دستهها از قبل مشخص میشوند، در خوشهبندی، دادهها به صورت خودکار و با توجه به ویژگیهای مشترکشان در خوشههای مجزا قرار میگیرند. این روش به کشف الگوها، شناسایی ناهنجاریها (اتفاقات غیرمعمول) و درک بهتر ساختار دادهها کمک میکند.
برای درک بهتر این تکنیک، فرض کنید کیسهای پر از آبنباتهای رنگی دارید و قصد دارید آنها را مرتب کنید، اما هیچ برچسبی برای دستهبندی مانند «آبنباتهای شکلاتی» یا «آبنباتهای میوهای» ندارید. در این حالت، خوشهبندی به شما کمک میکند تا دادهها را بر اساس ویژگیهای مشابه به گروههای مختلف تقسیم کنید. به عنوان مثال:
خوشهبندی بر اساس رنگ: ممکن است آبنباتهای قرمز در یک خوشه و آبنباتهای زرد و سبز در خوشههای دیگر قرار گیرند.
خوشهبندی بر اساس شکل: الگوریتمهای خوشهبندی ممکن است آبنباتهای قلبی را در یک خوشه و آبنباتهای گرد را در خوشهای دیگر قرار دهند.
این تکنیک به ویژه برای تجزیه و تحلیل دادههای پیچیده که نیاز به دستهبندی دستی ندارند، مفید است. تحلیلگران دادهها معمولاً از نمودارها و ابزارهای بصری برای نمایش نتایج خوشهبندی استفاده میکنند تا روندها و توزیع دادهها را بهتر درک کنند.
الگوریتمهای خوشهبندی در دادهکاوی
الگوریتمهای مختلفی برای خوشهبندی وجود دارند که هر کدام با روشهای متفاوت دادهها را گروهبندی میکنند. در اینجا به برخی از مهمترین الگوریتمهای خوشهبندی اشاره میکنیم:
الگوریتم K-Means:
این الگوریتم دادهها را به تعداد از پیش تعیینشدهای خوشه (K) تقسیم میکند. با استفاده از مراکز خوشه (centroids)، نقاط داده به نزدیکترین مرکز خوشه تخصیص داده میشوند و مراکز خوشه بر اساس دادههای اختصاص دادهشده مجدداً محاسبه میشوند. این فرآیند ادامه مییابد تا زمانی که مراکز خوشه ثابت شوند. این روش معمولاً برای دستهبندی مشتریان بر اساس ویژگیهای جمعیتی و رفتار خرید آنها استفاده میشود.
الگوریتم خوشهبندی سلسلهمراتبی (Hierarchical Clustering):
در این روش، خوشهها به صورت سلسلهمراتبی ایجاد میشوند و بر اساس شباهت با یکدیگر ادغام میشوند. این الگوریتم برای دستهبندی مقالات خبری یا دستهبندی موضوعات پیچیده به کار میرود.
الگوریتم DBSCAN (Density-Based Spatial Clustering of Applications with Noise):
این الگوریتم خوشهها را بر اساس تراکم دادهها شناسایی میکند. برخلاف سایر روشها، نیاز به تعیین تعداد خوشهها از پیش ندارد و قادر است با دادههای پرت (outliers) نیز به خوبی مقابله کند. یکی از کاربردهای این الگوریتم شناسایی خوشههای کهکشانها در دادههای نجومی است.
کاربردهای تکنیک خوشهبندی در دادهکاوی
تکنیک خوشهبندی به دلیل این که نیازی به دادههای برچسبدار ندارد و جزء یادگیری نظارتنشده (Unsupervised Learning) به شمار میرود، در موقعیتهایی که دادههای حجیم و پیچیده وجود دارند و امکان برچسبگذاری دادهها وجود ندارد، بسیار مفید است. برخی از کاربردهای این تکنیک عبارتند از:
بخشبندی بازار و بازاریابی هدفمند:
کسبوکارها میتوانند از خوشهبندی برای دستهبندی مشتریان بر اساس ویژگیهایی مانند سابقه خرید و رفتار خرید استفاده کنند. به عنوان مثال، یک فروشگاه لباس میتواند مشتریانی که به خرید لباسهای ورزشی علاقه دارند را در یک خوشه قرار دهد و سپس کمپینهای بازاریابی هدفمند برای این گروه راهاندازی کند.
طراحی چتبات برای خدمات مشتری:
خوشهبندی میتواند به شناسایی نیازها و سوالات رایج مشتریان کمک کند و چتباتها را قادر سازد تا پاسخهای خود را بر اساس خوشهها و نیازهای متداول مشتریان ارائه دهند. این امر به بهبود تجربه مشتری و کاهش زمان پاسخگویی کمک میکند.
تشخیص و سازماندهی تصاویر در رسانههای اجتماعی:
پلتفرمهای رسانههای اجتماعی مانند فیسبوک از خوشهبندی برای شناسایی و سازماندهی تصاویر استفاده میکنند. به عنوان مثال، تصاویر تعطیلات ساحلی میتوانند به طور خودکار در یک خوشه قرار بگیرند تا دسترسی به آنها راحتتر باشد.
تشخیص ناهنجاریها در پیشگیری از تقلب:
بانکها و موسسات مالی از خوشهبندی برای شناسایی تراکنشهای مشکوک استفاده میکنند. تراکنشهایی که از الگوهای معمول خرج کردن مشتریان متفاوت هستند، ممکن است شناسایی شوند و برای بررسی بیشتر علامتگذاری شوند.
پیشنهاد فیلم و محتوا در پلتفرمهای آنلاین:
پلتفرمهای پخش آنلاین مانند نتفلیکس از خوشهبندی برای پیشنهاد فیلمها و محتوا به کاربران استفاده میکنند. این الگوریتمها فیلمها را بر اساس ویژگیهایی مانند ژانر، کارگردان و بازیگران خوشهبندی کرده و سپس آنها را به مخاطبان بر اساس سلیقههای مشابه پیشنهاد میدهند.

ردیابی الگوها در داده کاوی
ردیابی الگو یکی از تکنیکهای مهم دادهکاوی است که به تحلیلگران این امکان را میدهد تا الگوهای مکرر و روابط معنادار در دادهها را شناسایی کرده و استنتاجهای مبتنی بر آنها به دست آورند. این استنتاجها میتوانند به تصمیمگیریهای تجاری کمک کرده و بر سود نهایی شرکت تأثیر مثبتی بگذارند.
مثال سادهای برای درک این تکنیک: فرض کنید صاحب یک وبسایت تجارت الکترونیک میخواهد بداند چه عواملی بر میزان رضایت مشتری تأثیرگذار هستند. تحلیلگر داده، اطلاعاتی از خریدهای مشتری، محصولات، و تعاملات با خدمات مشتری جمعآوری میکند. با استفاده از ردیابی الگو، ممکن است الگوهای زیر کشف شود:
مشتریانی که محصولاتی با قیمت بالاتر خریداری میکنند، رضایت بیشتری دارند.
مشتریانی که کالای خود را با تأخیر دریافت کردهاند، نظرات منفی بیشتری ثبت میکنند.
مشتریانی که با خدمات مشتری تعامل مثبت دارند، احتمال خرید مجددشان بیشتر است.
این الگوها به کسبوکارها کمک میکند تا بر بهبود تجربه مشتری متمرکز شوند. آنها میتوانند با تغییراتی در حمل و نقل، خدمات مشتری و کیفیت محصولات، تجربه کلی مشتری را بهبود بخشند. بنابراین، با استفاده از این الگوها، سازمانها میتوانند تصمیمات بهتری بگیرند و به اهداف تجاری خود نزدیکتر شوند.
الگوریتمهای ردیابی الگو در دادهکاوی
در دادهکاوی، تکنیکهای مختلفی برای شناسایی الگوها و روابط پنهان در دادهها وجود دارند. این الگوریتمها به کسبوکارها کمک میکنند تا روندها و تغییرات مکرر در دادهها را شناسایی کرده و پیشبینیهایی در مورد رفتار آینده داشته باشند. در ادامه، به برخی از رایجترین الگوریتمهای ردیابی الگو اشاره میکنیم:
الگوریتمهای تشخیص الگوی ترتیبی (Sequential Pattern Mining):
این الگوریتمها برای شناسایی دنبالههای مکرر رویدادها یا آیتمها که به ترتیب خاصی در طول زمان رخ میدهند، طراحی شدهاند. الگوریتمهایی مانند GSP، PrefixSpan و SPADE از نمونههای معروف این دسته هستند.
تکنیکهای دادهکاوی برای تحلیل سری زمانی (Time Series Analysis):
این روشها برای تجزیه و تحلیل دادههایی که در فواصل زمانی منظم (روزانه، ماهانه و غیره) جمعآوری میشوند، به کار میروند. الگوریتمهای Moving Average، ARIMA و Exponential Smoothing از رایجترین الگوریتمها برای تحلیل سری زمانی هستند.
مدل مارکوف پنهان (Hidden Markov Model – HMM):
این مدل برای ردیابی تغییرات در وضعیت سیستمها استفاده میشود. مدل مارکوف پنهان به ما اجازه میدهد تغییرات پنهان در سیستم را بر اساس دنبالههای خروجی مشاهده شده شبیهسازی کنیم.
کاربردهای ردیابی الگو در دادهکاوی
ردیابی الگوها در دادهکاوی میتواند به کشف روابط پنهان و روندهای غیرقابل مشاهده کمک کند. این الگوها میتوانند اطلاعات ارزشمندی برای تصمیمگیریهای کسبوکار فراهم کنند. در ادامه به چند کاربرد از ردیابی الگو در دادهکاوی اشاره میکنیم:
کاربرد در بازاریابی و فروش:
کسبوکارها میتوانند با ردیابی الگوهای خرید مشتریان، پیشنهادات بهتری ارائه دهند. برای مثال، یک فروشگاه آنلاین لوازم ورزشی با ردیابی الگو متوجه میشود که مشتریانی که کفشهای دویدن میخرند، معمولاً جوراب ورزشی و بطری آب نیز خریداری میکنند. این الگو میتواند به فروشگاه کمک کند تا محصولات مرتبط را در کنار هم تبلیغ کند و فروش خود را افزایش دهد.
مدیریت ارتباط با مشتری (CRM):
یک شرکت مخابراتی میتواند با ردیابی الگوهای تماس مشتریان با خدمات مشتری، مشتریانی که صورتحسابهای معوقه دارند را شناسایی کرده و به پیشگیری از مشکلات پرداختی کمک کند. این پیشبینیها به شرکتها کمک میکند تا به موقع به نیازهای مشتریان پاسخ دهند.
پیشبینی تقاضا:
شرکتهای خردهفروشی میتوانند از تکنیکهای ردیابی الگو برای تجزیه و تحلیل فروش فصلی استفاده کنند. با شناسایی الگوهای فصلی و تعطیلات، این کسبوکارها میتوانند موجودی انبار خود را بهتر مدیریت کرده و از کمبود کالا در مواقع نیاز جلوگیری کنند.
تشخیص تقلب:
بانکها میتوانند با تجزیه و تحلیل تراکنشهای مالی، الگوهای غیرمعمول مانند خریدهای بزرگ از مکانهای ناآشنا را شناسایی کرده و از تقلبهای مالی جلوگیری کنند. این الگوریتمها به شناسایی تراکنشهای مشکوک کمک میکنند و امنیت سیستمهای مالی را بهبود میبخشند.

تکنیک های داده کاوی رگرسیون چیست؟
رگرسیون یکی از مهمترین تکنیکهای دادهکاوی است که برای کشف روابط میان متغیرها و پیشبینی مقادیر آینده بر اساس دادههای موجود استفاده میشود. این روش به دانشمندان داده کمک میکند تا الگوهای پنهان و ارتباطات بین متغیرهای مختلف را شناسایی کرده و تصمیمات آگاهانهتری بگیرند.
به طور کلی، رگرسیون به بررسی و مدلسازی ارتباط میان متغیر مستقل و متغیر وابسته میپردازد. برای مثال، تحلیلگران داده میتوانند از تکنیکهای رگرسیون برای پیشبینی قیمت یک محصول بر اساس عواملی مانند تقاضا، تورم یا هزینههای تولید استفاده کنند.
تکنیکهای رگرسیون در دادهکاوی امکانات متعددی را برای تحلیل دادهها و تصمیمگیریهای بهتر فراهم میکنند:
کشف روابط پنهان بین متغیرها:
رگرسیون میتواند ارتباطات پیچیده و الگوهای پنهان میان متغیرهای مختلف در مجموعه دادهها را شناسایی کند؛ روابطی که ممکن است به سادگی قابل تشخیص نباشند.
پیشبینی نتایج آینده:
با استفاده از مدلهای رگرسیون، میتوان تغییرات آینده را پیشبینی کرد و تصمیمگیریهای دقیقتری انجام داد. این ویژگی در حوزههایی مانند پیشبینی فروش، قیمتگذاری و مدیریت موجودی اهمیت دارد.
ارائه شواهد مبتنی بر داده:
رگرسیون از حدس و گمان فراتر میرود و شواهد کمی و مبتنی بر دادهها را برای تحلیلها و نتیجهگیریهای علمی فراهم میکند.
در دادهکاوی، چندین نوع مدل رگرسیون وجود دارد که هر کدام برای کاربردها و مسائل خاصی مناسب هستند:
رگرسیون خطی (Linear Regression):
این مدل سادهترین نوع رگرسیون است و برای پیشبینی مقادیر عددی بر اساس یک یا چند متغیر مستقل استفاده میشود.
مثال: پیشبینی قیمت خانه بر اساس متراژ و تعداد اتاقها.
رگرسیون لجستیک (Logistic Regression):
این تکنیک برای پیشبینی متغیرهای طبقهبندی (مانند بله/خیر یا موفق/ناموفق) استفاده میشود.
مثال: پیشبینی اینکه آیا یک مشتری خرید خواهد کرد یا خیر.
رگرسیون چندگانه (Multiple Regression):
این مدل برای تحلیل تأثیر چند متغیر مستقل بر یک متغیر وابسته استفاده میشود.
مثال: پیشبینی فروش بر اساس تبلیغات، قیمت محصول و فصل.
رگرسیون غیرخطی (Non-Linear Regression):
زمانی که رابطه میان متغیرها خطی نباشد، از این مدل استفاده میشود.
مثال: تحلیل رشد جمعیت یا پیشبینی سود در طول زمان.
رگرسیون ریدج و لاسو (Ridge & Lasso Regression):
این مدلها برای کاهش پیچیدگی مدل و جلوگیری از بیشبرازش (Overfitting) استفاده میشوند.
مثال: تحلیل دادههای بزرگ با تعداد زیادی متغیر مستقل.

هدف از تکنیک های داده کاوی برای تشخیص ناهنجاری چیست؟
تشخیص ناهنجاری (Anomaly Detection) یکی از تکنیکهای کلیدی در دادهکاوی است که برای شناسایی دادههای غیرعادی، ناهنجار یا پرت در یک مجموعه داده استفاده میشود. این تکنیکها به دانشمندان داده کمک میکنند تا رفتار غیرمعمول در دادهها را کشف کرده و بر اساس آنها تصمیمات مؤثری بگیرند.
درک و استفاده از تکنیکهای تشخیص ناهنجاری به دلایل مختلفی ضروری است، از جمله:
افزایش دقت مدلها: دادههای پرت میتوانند کیفیت مدلهای یادگیری ماشین را کاهش دهند؛ بنابراین حذف یا مدیریت این دادهها در مراحل پیشپردازش بسیار مهم است.
شناسایی رفتارهای غیرمعمول: شناسایی ناهنجاریها میتواند به کشف الگوهای خاص یا هشدار درباره مشکلات بالقوه کمک کند.
بهبود تحلیل دادهها: این تکنیکها دیدگاه واضحتری از مجموعه دادهها فراهم میکنند و به تصمیمگیری بهتر کمک میکنند.
کاربردهای تشخیص ناهنجاری
تکنیکهای تشخیص ناهنجاری در بسیاری از صنایع و حوزهها مورد استفاده قرار میگیرند. در ادامه چند نمونه از کاربردهای رایج آورده شده است:
1. تشخیص تقلب در تراکنشهای مالی:
بانکها و مؤسسات مالی از تکنیکهای دادهکاوی برای شناسایی فعالیتهای غیرمعمول مانند تراکنشهای مشکوک یا کلاهبرداری استفاده میکنند.
مثال: شناسایی تراکنشهای بزرگ از مکانهای ناآشنا.
2. پیشگیری از نقص در سیستمها:
در صنایع تولیدی یا فناوری اطلاعات، تشخیص ناهنجاری میتواند برای شناسایی مشکلات احتمالی در عملکرد تجهیزات یا سرورها مفید باشد.
مثال: کشف تغییرات غیرعادی در دما یا فشار سیستمهای صنعتی.
3. تحلیل فروش و بازاریابی:
بررسی افزایش یا کاهش ناگهانی فروش و شناسایی عواملی که باعث تغییرات ناگهانی در رفتار مشتریان میشوند.
مثال: تشخیص افزایش غیرمنتظره فروش یک محصول خاص.
4. تحلیل پزشکی:
در علوم پزشکی، این تکنیکها برای شناسایی دادههای غیرعادی در آزمایشها یا پیشبینی بیماریها استفاده میشوند.
مثال: شناسایی علائم غیرمعمول در نتایج آزمایشهای بیماران.
5. امنیت سایبری:
شناسایی رفتارهای غیرمعمول در شبکهها یا سیستمهای کامپیوتری برای جلوگیری از حملات سایبری یا دسترسیهای غیرمجاز.
مثال: تشخیص ورود غیرمجاز به سیستم در ساعتهای غیرمعمول.

تکنیک تشخیص الگوهای متوالی در داده کاوی چیست؟
تشخیص الگوهای متوالی یکی از تکنیکهای قدرتمند دادهکاوی است که برای کشف روابط زمانی میان رویدادها یا تراکنشها در یک مجموعه داده استفاده میشود. این روش به شناسایی دنبالههایی از وقایع میپردازد که به ترتیب مشخصی تکرار میشوند و از این طریق، بینشهای ارزشمندی درباره رفتار کاربران، روندها، و روابط بین دادهها ارائه میدهد.
هدف اصلی این تکنیک، کشف دنبالههای معنادار از رویدادهاست که میتوانند به تصمیمگیریهای بهتری در حوزههای مختلف کمک کنند. برخی از اهداف اصلی عبارتاند از:
شناسایی رفتارهای تکراری: مانند الگوی خرید مشتریان یا استفاده از خدمات.
پیشبینی رویدادهای آینده: با استفاده از الگوهای شناسایی شده، میتوان رفتار آینده کاربران را پیشبینی کرد.
بهینهسازی فرآیندها: مانند مدیریت موجودی انبار یا طراحی بهتر کمپینهای تبلیغاتی.
چگونگی عملکرد تکنیک تشخیص الگوهای متوالی
جمعآوری دادههای تراکنش:
دادهها باید شامل اطلاعاتی درباره ترتیب وقوع رویدادها باشند. برای مثال، خریدهای مشتری در بازههای زمانی مختلف.
شناسایی الگوهای متوالی:
الگوریتمها به دنبال دنبالههای پرتکرار میگردند که در طول زمان رخ میدهند.
مثال: مشتریانی که محصول A را خریداری میکنند، اغلب در ادامه محصول B را خریداری میکنند.
تحلیل و استخراج دانش:
الگوهای کشف شده به تحلیلگران داده کمک میکنند تا روندها را شناسایی و استراتژیهای مناسب طراحی کنند.
الگوریتمهای رایج برای تشخیص الگوهای متوالی
- Apriori Algorithm for Sequential Patterns:
این الگوریتم به شناسایی دنبالههای پرتکرار کمک میکند و یکی از پرکاربردترین روشها در تحلیل تراکنشهای متوالی است. PrefixSpan:
این الگوریتم از یک روش تقسیمبندی برای کشف الگوهای متوالی استفاده میکند و در مقایسه با روش Apriori عملکرد بهتری در مجموعه دادههای بزرگ دارد.SPADE (Sequential Pattern Discovery using Equivalence classes):
این روش از گرافها برای شناسایی الگوهای متوالی استفاده میکند و به دلیل سرعت بالا شناخته شده است.GSP (Generalized Sequential Pattern):
الگوریتمی مبتنی بر رویدادهای متوالی که قادر به مدیریت محدودیتهای پیچیدهتر در کشف الگوهاست.

روش های پیش بینی در داده کاوی
پیشبینی یکی از تکنیکهای اصلی در دادهکاوی است که برای شناسایی و درک روندها، الگوها، و روابط میان متغیرها به کار میرود. هدف از این روش، ارائه دیدگاهی دقیق از آینده بر اساس دادههای تاریخی و حال است. پیشبینیها به تصمیمگیران کمک میکنند تا با برنامهریزی بهتر، عملکرد خود را بهبود بخشند و ریسکها را کاهش دهند.
مزایای استفاده از پیشبینی در دادهکاوی
تصمیمگیری آگاهانه:کمک به مدیران در اتخاذ تصمیمات استراتژیک با استفاده از تحلیل نتایج پیشبینیشده.
مثال: پیشبینی نرخ ریزش مشتریان و طراحی کمپینهای حفظ مشتری.
بهینهسازی منابع:
پیشبینی تقاضا برای محصولات یا خدمات، تخصیص بهینه منابع را تسهیل میکند.
مثال: مدیریت موجودی کالا در خردهفروشی.
مدیریت ریسک:
شناسایی تهدیدات بالقوه و کاهش خطرات با اقدامات پیشگیرانه.
مثال: پیشبینی احتمال بروز مشکلات فنی در تجهیزات.
کاربردهای پیشبینی در صنایع مختلف
بازاریابی و فروش:
پیشبینی رفتار مشتریان و طراحی کمپینهای هدفمند.
مثال: تحلیل رفتار مشتریان برای پیشنهاد محصولات مناسب.حوزه سلامت:
پیشبینی شیوع بیماریها و طراحی استراتژیهای درمانی.مدیریت زنجیره تأمین:
پیشبینی تقاضای محصولات و بهینهسازی موجودی انبار.مالی و بیمه:
پیشبینی ریسکهای مالی، ورشکستگیها، و کلاهبرداریها.فناوری اطلاعات:
شناسایی مشکلات احتمالی در سیستمها و پیشگیری از خرابیهای بزرگ.
مراحل اجرای پیشبینی در دادهکاوی
جمعآوری و آمادهسازی دادهها:
دادههای تمیز، ساختاریافته و جامع برای پیشبینی دقیق ضروری است.انتخاب مدل مناسب:
انتخاب مدل بر اساس نوع دادهها و هدف پیشبینی.آموزش مدل:
مدل با استفاده از دادههای آموزشی آموزش داده میشود تا بتواند الگوها را شناسایی کند.ارزیابی مدل:
بررسی دقت مدل با استفاده از معیارهایی مانند RMSE، MAE، و R².استفاده از مدل برای پیشبینی:
اعمال مدل بر روی دادههای جدید برای پیشبینی رویدادهای آینده.

تکنیک قوانین انجمنی در داده کاوی چیست؟
قوانین انجمنی (Association Rules) یکی از تکنیکهای مهم در دادهکاوی است که به کشف روابط معنادار و الگوهای مکرر بین مجموعهای از دادهها میپردازد. این روش به شناسایی همبستگیها و وابستگیها بین متغیرها کمک میکند و اغلب در تحلیل رفتار مشتری، مدیریت زنجیره تأمین، و بازاریابی به کار میرود.
این تکنیک به شناسایی روابط اگر-آنگاه (If-Then) میان مجموعهای از آیتمها یا متغیرها میپردازد.
یک قانون انجمنی به صورت زیر تعریف میشود:
“اگر A، آنگاه B”
به این معنا که اگر یک مشتری یا دادهای ویژگی A را داشته باشد، به احتمال زیاد ویژگی B را نیز خواهد داشت.
پارامترهای اصلی در قوانین انجمنی
- Support (حمایت): فراوانی وقوع مجموعهای از آیتمها در کل دادهها.
- Confidence (اعتماد):احتمال وقوع B به شرط وقوع A.
- Lift (ارتقاء): نشان میدهد که احتمال وقوع B در صورت وجود A چقدر بیشتر از زمانی است که A وجود نداشته باشد.
الگوریتمهای رایج قوانین انجمنی
الگوریتم Apriori:
یکی از معروفترین روشها برای کشف مجموعههای مکرر و استخراج قوانین انجمنی. این الگوریتم بر پایه اصل کاهش تدریجی کار میکند، به این معنا که آیتمهایی با میزان حمایت کمتر از آستانه مشخص کنار گذاشته میشوند.الگوریتم Eclat:
این الگوریتم با استفاده از تقاطع مجموعهها، مجموعههای مکرر را کشف میکند. این روش برای دادههای با ابعاد بالا مناسبتر است.الگوریتم FP-Growth (Frequent Pattern Growth):
یک روش پیشرفتهتر که به جای تولید مجموعههای کاندیدا، از یک ساختار درختی برای کشف الگوها استفاده میکند و کارایی بالایی در تحلیل دادههای بزرگ دارد.

شبکه عصبی در داده کاوی
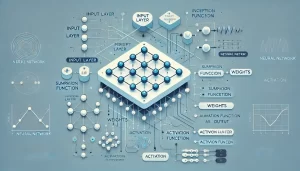
شبکههای عصبی مصنوعی (Artificial Neural Networks یا ANN) یکی از تکنیکهای پیشرفته دادهکاوی هستند که از ساختار و عملکرد نورونهای مغز انسان الهام گرفتهاند. این تکنیکها بهطور خاص برای تحلیل و شناسایی روابط پیچیده و غیرخطی در دادهها استفاده میشوند و در حل مسائل پیشبینی، طبقهبندی، و خوشهبندی کاربرد گستردهای دارند.
ساختار شبکه عصبی
شبکه عصبی مصنوعی شامل سه بخش اصلی است:
لایه ورودی (Input Layer):
اطلاعات خام به این لایه وارد میشود. هر نورون در این لایه نماینده یکی از ویژگیهای داده است.
لایههای پنهان (Hidden Layers):
شامل تعدادی نورون است که با استفاده از توابع ریاضی و وزنهای یادگیری، الگوها و روابط پیچیده در دادهها را شناسایی میکند. تعداد و عمق این لایهها میتواند بر قدرت مدل تأثیر بگذارد.
لایه خروجی (Output Layer):
نتایج نهایی، مانند پیشبینی یا طبقهبندی، از این لایه به دست میآید.
عملکرد شبکه عصبی
شبکه عصبی با یادگیری از دادهها، به مرور زمان وزنهایی را برای ارتباطات بین نورونها تنظیم میکند. این فرآیند در دو مرحله انجام میشود:
مرحله آموزش (Training):
مدل با استفاده از دادههای برچسبدار (Supervised Learning) یا بدون برچسب (Unsupervised Learning)، روابط بین متغیرها را یاد میگیرد.
مرحله اعتبارسنجی و آزمایش (Validation & Testing):
عملکرد مدل بر اساس دادههای جدید سنجیده میشود تا از دقت و کارایی آن اطمینان حاصل شود.