

ترنسفورمر در یادگیری عمیق – مدل Transformer به زبان ساده
با رشد و توسعه مدلهای «ترنسفورمر» (Transformer)، یادگیری عمیق به پیشرفتهای چشمگیری دست یافته است. این معماری نوآورانه، تحولی در اصول «پردازش زبان طبیعی» (NLP) ایجاد کرده و همچنین کاربردهای هوش مصنوعی را به مسائل متنوعی گسترش داده است. در واقع، مدلهای ترنسفورمر نوع خاصی از شبکههای عصبی هستند که توسط شرکتهای بزرگی مانند OpenAI استفاده میشوند و همین امر به محبوبیت چشمگیری در بین متخصصان این حوزه منجر شده است.
در این مقاله، با مفهوم و ساختار ترنسفورمر در یادگیری عمیق آشنا میشویم و به برخی از مدلهای معروف آن نگاهی خواهیم انداخت؛ ساختاری که الهامبخش بسیاری از دانشمندان داده و علاقهمندان به این حوزه بوده است.
در این مطلب ابتدا توضیح میدهیم که ترنسفورمر چیست و به ساختار مدلهای ترنسفورمر در یادگیری عمیق میپردازیم. سپس به چند نمونه کاربردی و روشهای ارزیابی این مدلها اشاره میکنیم و در انتها، مقایسهای میان ترنسفورمر و دو ساختار پرکاربرد دیگر ارائه خواهیم داد.
اگر به هوش مصنوعی علاقه دارید بیاتو ای آی

تعریف ترنسفورمر
طراحی و توسعه ترنسفورمرها با هدف حل مسئله «تبدیل توالی» (Sequence Transduction) یا «ترجمه ماشینی» (Machine Translation) شکل گرفته است. به عبارتی دیگر، ترنسفورمرها در یادگیری عمیق برای تبدیل یک دنباله یا توالی ورودی به دنبالهای خروجی مورد استفاده قرار میگیرند؛ این توانایی تبدیل توالیها است که به این ساختارها نام «ترنسفورمر» را داده است. در ادامه، به مدلهای برجسته ترنسفورمر و تاریخچه شکلگیری آنها میپردازیم.

مدل ترنسفورمر در یادگیری عمیق
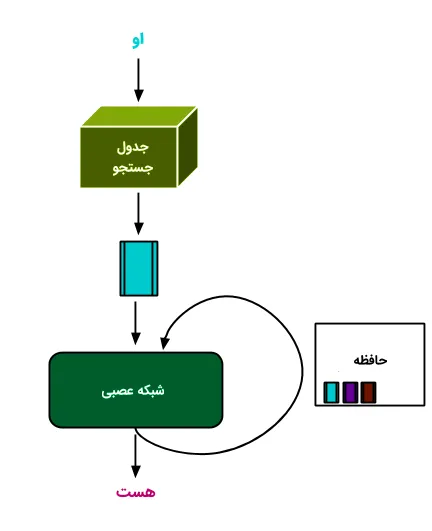
مدل ترنسفورمر یک شبکه عصبی است که از دادههای ترتیبی برای یادگیری و تولید دادههای جدید استفاده میکند. به عبارت دیگر، ترنسفورمرها نوعی مدل هوش مصنوعی هستند که با تحلیل الگوهای موجود در دادههای متنی، نحوه نگارش متون به زبان انسان را میآموزند و قادرند نمونههای جدیدی تولید کنند. این مدلها به عنوان پیشرفتهترین مدلهای پردازش زبان طبیعی (NLP) شناخته میشوند و از ساختار «رمزگذار-رمزگشا» (Encoder-decoder) بهره میبرند.
برخلاف ساختارهای مشابه که از «شبکههای عصبی بازگشتی» (RNN) برای استخراج اطلاعات ترتیبی استفاده میکنند، ترنسفورمرها فاقد ویژگی بازگشتی هستند. طراحی این مدلها به گونهای است که میتوانند ارتباط میان بخشهای مختلف ورودی را تحلیل کرده و آن را درک کنند. برای انجام این تحلیل، مدلهای ترنسفورمر تنها بر روی تکنیک ریاضیاتی به نام «مکانیزم توجه» (Attention) تمرکز دارند.
تاریخچه شکلگیری ترنسفورمر
در سال ۲۰۱۷ ایده مدلهای ترنسفورمر برای اولین بار در مقالهای با عنوان «Attention is All You Need» از سوی شرکت گوگل مطرح شد و از آن زمان به یکی از تاثیرگذارترین نوآوریها در حوزه یادگیری ماشین تبدیل گشته است. این مفهوم پیشگامانه نه تنها یک پیشرفت نظری محسوب میشود، بلکه بهطور عملی در بسته نرمافزاری Tensor2Tensor و کتابخانه TensorFlow پیادهسازی شده است. همچنین، گروه تحقیقاتی NLP دانشگاه هاروارد راهنماییهایی برای پیادهسازی این مقاله با استفاده از کتابخانه PyTorch در زبان برنامهنویسی پایتون ارائه داد.
مدل معرفی شده را میتوان سرآغاز توسعه مدلهای زبانی بزرگ مانند BERT دانست. در سال ۲۰۱۸، این تحول به نقطه عطفی در حوزه پردازش زبان طبیعی (NLP) تبدیل شد و در سال ۲۰۲۰، محققان شرکت OpenAI مدل زبانی GPT-3 را معرفی کردند. کاربران در همان هفتههای ابتدایی، این مدل را در زمینههای مختلفی مانند هنر، برنامهنویسی و موسیقی به چالش کشیدند.
در سال ۲۰۲۱، پژوهشگران دانشگاه استنفورد در مقالهای این نوآوریها را «مدلهای پایه» (Foundation Models) نامیدند، که نشاندهنده نقش اساسی آنها در بازتعریف مفهوم هوش مصنوعی بود. این پژوهش بر نقش مدلهای ترنسفورمر در گسترش مرزهای هوش مصنوعی و ایجاد فرصتهای جدید در این حوزه متمرکز است.
از مدلهای RNN مانند LSTM به ترنسفورمرها
قبل از معرفی مدل ترنسفورمر در یادگیری عمیق، مدلهای بازگشتی یا RNN برای پردازش دادههای ترتیبی استفاده میشد. مدل RNN شباهت زیادی به شبکه عصبی «پیشخور» (Feedforward) دارد، اما دادهها را بهصورت ترتیبی پردازش میکند. ترنسفورمرها در یادگیری عمیق از ساختار رمزگذار-رمزگشا مدلهای بازگشتی الهام گرفتهاند، با این تفاوت که بهجای استفاده از چرخه بازگشتی، هر مدل ترنسفورمر بر اساس مکانیزم Attention فعالیت میکند.
ترنسفورمرها تحولی اساسی در یادگیری عمیق ایجاد کردهاند، بهطوری که عملکرد RNN را بهبود داده و چارچوبی جدید برای حل مسائل متنوعی مانند خلاصهسازی متون، توصیف تصاویر (Image Captioning) و شناسایی گفتار فراهم کردهاند. بهطور کلی، دو مشکل عمده در RNNها وجود دارد که ترنسفورمرها آنها را برطرف میکنند:
پردازش دادهها بهصورت متوالی: در RNN، دادهها به ترتیب پردازش میشوند که این روش از تواناییهای محاسبات موازی واحدهای پردازش گرافیکی (GPU) استفاده نمیکند و موجب کاهش سرعت آموزش مدل میشود.
کاهش کارایی در پردازش دادههای پراکنده: در مواردی که بخشهای مختلف ورودی از هم فاصله دارند، RNNها بهخوبی عمل نمیکنند. دلیل این مشکل، انتقال دادهها در هر لایه و احتمال فراموش شدن یا تغییر اطلاعات در زنجیرههای طولانی است.
استفاده از مدلهای ترنسفورمر در یادگیری عمیق، بهویژه در پردازش زبان طبیعی (NLP)، این محدودیتها را برطرف کرده است. مزایایی نظیر تمرکز بر کلمات فارغ از فاصله آنها از یکدیگر و بهبود سرعت عملکرد از طریق مکانیزم Attention از ویژگیهای برتر ترنسفورمر است.
بنابراین، ترنسفورمر نسخه پیشرفتهتری از RNN محسوب میشود. در ادامه، ساختار ترنسفورمر در یادگیری عمیق را بهطور خلاصه بررسی خواهیم کرد.
ساختار ترنسفورمر در یادگیری عمیق چگونه است؟
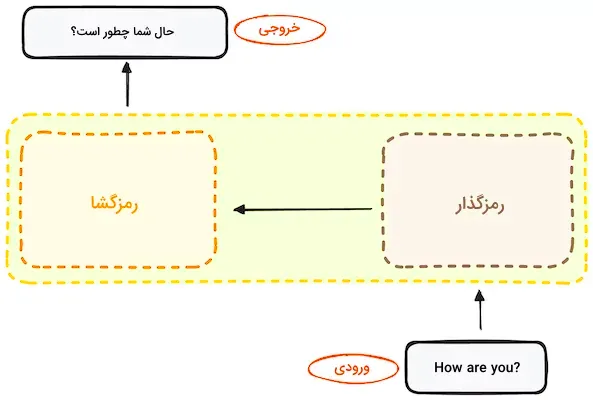
همانطور که در ابتدای مطلب اشاره شد، اولین کاربرد ترنسفورمر در ترجمه ماشینی و تبدیل توالی ورودی به توالی خروجی بوده است. این مدل، بدون نیاز به استفاده از شبکه RNN یا محاسبات کانولوشنی، با استفاده از روش «خودنگرش» (Self-Attention) کار میکند. حفظ ساختار رمزگذار-رمزگشا را میتوان بهعنوان ویژگی اصلی ترنسفورمرها در نظر گرفت. بهعنوان مثال، در ترجمه زبانی، ترنسفورمر بهصورت یک جعبه سیاه عمل میکند؛ ورودی به شکل یک جمله در یک زبان دریافت میشود و خروجی به زبان دیگر ارائه میگردد.
اگر دقیق تر شویم، می بینیم که این جعبه سیاه از دو بخش اصلی تشکیل شده است:
بخش رمزگذار: ورودی را دریافت کرده و به شکل ماتریسی از ویژگیها تبدیل میکند. برای مثال، جمله انگلیسی “?How are you” بهعنوان ورودی استفاده میشود.
بخش رمزگشا: خروجی بخش رمزگذار را دریافت کرده و آن را به یک جمله در زبان مقصد تبدیل میکند. برای نمونه، خروجی در این مثال جمله «چطور هستید؟» خواهد بود.
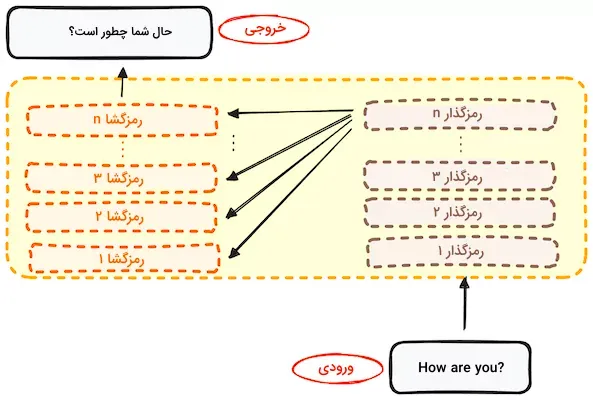
رمزگذار و رمزگشا در ترنسفورمر، از پشتهای با چندین لایه یکسان تشکیل شدهاند. بخش رمزگذار ساختار یکسانی دارد و ورودی از تمام لایههای آن عبور میکند. همچنین بخش رمزگشا نیز ساختاری مشابه دارد و ورودی خود را از آخرین لایه رمزگذار و لایه قبلی تأمین میکند. ساختار استاندارد شامل ۶ لایه برای رمزگذار و ۶ لایه برای رمزگشا است، اگرچه این تعداد میتواند بسته به نیاز تغییر کند.
بررسی ساختار رمزگذارو مراحل آن
بخش مهم و اساسی در معماری ترنسفورمر ،رمزگذار است و هدف آن تبدیل توکنهای ورودی به موجودیتهایی با مفهوم است. برخلاف مدلهای قدیمی که هر توکن بهصورت مجزا پردازش میشد، ساختار رمزگذار در ترنسفورمر، محتوای هر توکن را با حفظ انسجام دنباله ورودی استخراج میکند. در تصویر زیر، چیدمان کلی بخش رمزگذار قابل مشاهده است.
در ادامه هر کدام از مراحل ساختار رمزگذار را به تفکیک توضیح میدهیم.
مرحله ۱ – تعبیه ورودی
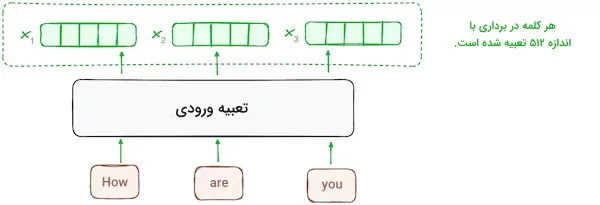
فرایند «تعبیه» (Embedding) یا ساخت بردار، فقط در پایینترین یا اولین لایه رمزگذار انجام میشود. در این مرحله، رمزگذار با استفاده از لایههای تعبیه، توکنهای ورودی (کلمات) را به بردارهای متناظر تبدیل میکند. این لایهها، محتوای ورودی را استخراج کرده و برای هر کلمه یک بردار عددی تشکیل میدهند. در ادامه، همه رمزگذارها لیستی از بردارها با اندازه ۵۱۲ دریافت میکنند. ورودی اولین لایه رمزگذار همان کلمات تعبیهشده به شکل بردار است، اما ورودی سایر رمزگذارها، خروجی رمزگذاری سطح پایینتر است.
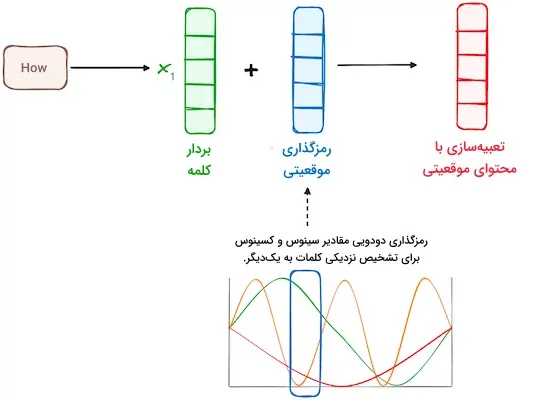
مرحله ۲ – رمزگذاری موقعیتی
از آنجا که ترنسفورمرها مکانیزم بازگشتی مشابه RNN ندارند، برای دستیابی به موقعیت هر توکن در دنباله، از «رمزگذاری موقعیتی» (Positional Encoding) استفاده میکنند. این روش موقعیت هر کلمه در جمله را تعیین میکند. پژوهشگران برای این منظور، ترکیبی از توابع سینوسی و کسینوسی را به کار گرفتهاند تا بردارهای موقعیتی را ایجاد کنند. این فرایند امکان استفاده از رمزگذاری موقعیتی برای جملات با طولهای مختلف را فراهم میآورد.
در این رویکرد، هر بُعد با استفاده از دو معیار فراوانی و انحراف موج، موقعیتهای مختلف را در بازهای بین ۱- و ۱ نمایش میدهد.
مرحله ۳ – پشته لایههای رمزگذار
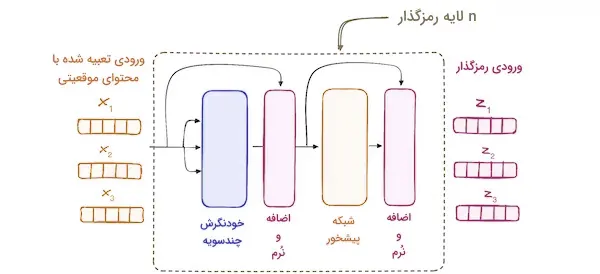
رمزگذار در مدل ترنسفورمر از پشتهای متشکل از چندین لایه مشابه تشکیل شده است که در نسخه اصلی ترنسفورمر، تعداد آنها به ۶ لایه میرسد. هر لایه رمزگذار، دنبالههای ورودی را به یک نمایش پیوسته و خلاصهشده تبدیل میکند که حاوی اطلاعات یادگرفتهشده از کل دنباله است.
این لایه شامل دو بخش اصلی زیر است:
- مکانیزم توجه «چندسویه» (Multi-headed)
- شبکه «تماممتصل» (Fully Connected)
همچنین، هر لایه رمزگذار به چند زیرلایه متصل است که پس از هر زیرلایه، یک لایه نرمالسازی قرار دارد.
مرحله ۱.۳ – مکانیزم توجه چندسویه
یکی ازبخش های لایه ی رمزگذار است. مکانیزم توجه «چندسویه» (Multi-Headed) در رمزگذار از نوعی مکانیزم توجه به نام «خودنگرش» (Self-Attention) بهره میبرد. این روش به مدل امکان میدهد که هر کلمه در ورودی را با سایر کلمات مرتبط کند. به عنوان مثال، در جمله “?How are you”، مدل رابطه بین کلمات “are” و “you” را میآموزد. این سازوکار با پردازش هر توکن ورودی، رمزگذار را قادر میسازد تا به بخشهای مختلف دنباله ورودی توجه کند.
امتیاز توجه، مطابق با اصول زیر محاسبه میشود:
- کوئری برداری است که نمایانگر هر کلمه یا توکن خاصی از دنباله ورودی است.
- کلید برداری مرتبط با یک کلمه یا توکن ورودی در مکانیزم توجه است.
- مقدار با کلید در ارتباط بوده و در تعیین خروجی لایه توجه تأثیرگذار است. زمانی که کوئری با کلید همخوانی دارد، امتیاز توجه افزایش یافته و مقدار مرتبط در خروجی ظاهر میشود.
با استفاده از اولین واحد خودنگرش، مدل قادر است اطلاعات متنی را از دنباله ورودی استخراج کند. بهجای اعمال یک تابع توجه منفرد، کوئریها، کلیدها و مقادیر بهصورت خطی و به تعداد h مرتبه محاسبه میشوند. برای هر نسخه از این مقادیر، مکانیزم توجه بهطور موازی اجرا میشود و خروجیای با ابعاد h تولید میکند. ساختار کامل این مکانیزم در تصویر زیر نمایش داده شده است.
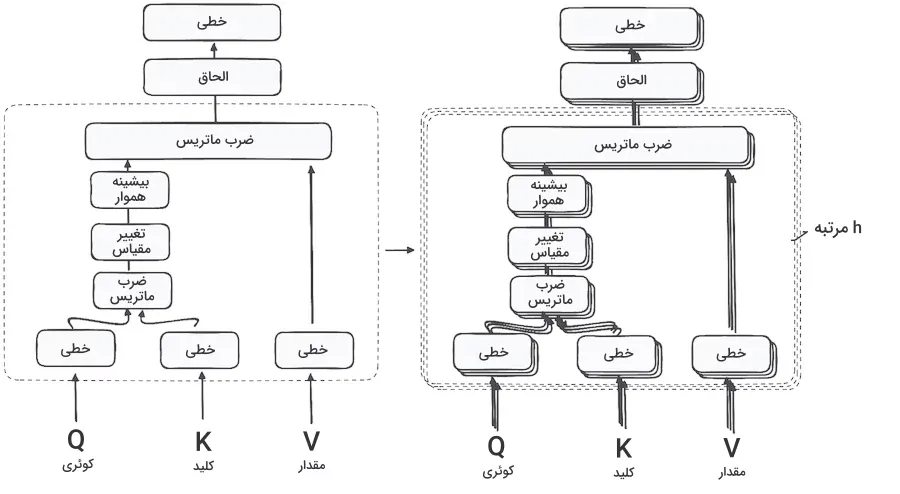
تحلیل معماری مکانیرم خودنگرش: ازتحلیل ضرب ماتریس تا ترکیب کلمات
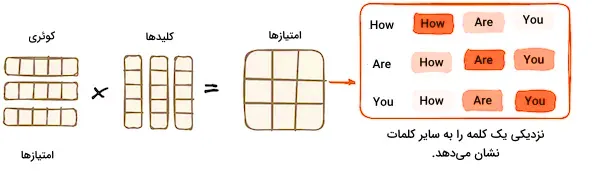
ضرب ماتریس – ضرب داخلی کوئری و کلید
زمانی که بردارهای کوئری، کلید، و مقدار از یک لایه خطی عبور میکنند، ضرب داخلی بین کوئریها و کلیدها انجام میشود و به تولید «ماتریس امتیاز» (Score Matrix) منجر میگردد. این ماتریس امتیاز، اهمیت هر کلمه را نسبت به سایر کلمات مشخص میکند و به هر کلمه امتیازی میدهد که بیانگر ارتباط آن با کلمات دیگر در یک بازه زمانی مشابه است. این فرآیند، کوئریها را به کلیدهای متناظر نگاشت میکند.
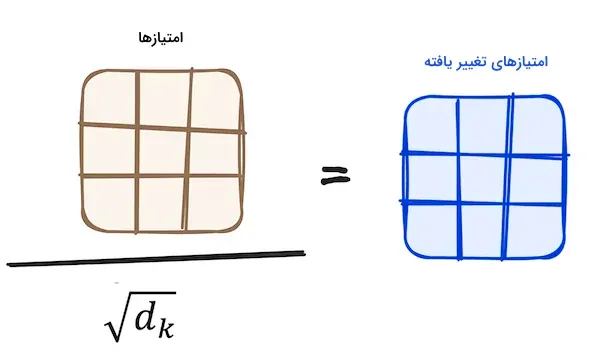
کاهش اندازه امتیازهای توجه
برای کاهش ابعاد امتیازها، هر عنصر از ماتریس امتیاز بر جذر اندازه بردارهای کوئری و کلید تقسیم میشود. این مرحله منجر به تولید مقادیر گرادیان پایدارتر میشود.
اعمال تابع بیشینه هموار بر امتیازها
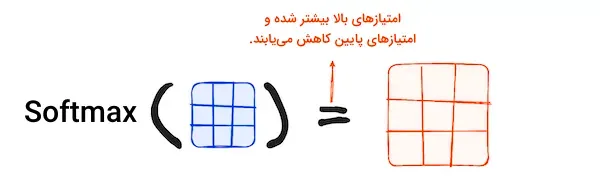
در مرحله بعد، برای تولید مقادیر وزنی، از تابع «بیشینه هموار» (Softmax) بر تمامی امتیازها استفاده میشود. خروجی این تابع به شکل احتمالاتی است و بین ۰ تا ۱ متغیر است. تابع بیشینه هموار باعث افزایش اهمیت امتیازهای بالاتر و کاهش اهمیت امتیازهای پایین میشود و مدل را قادر میسازد تا کلمات مهم را بهتر شناسایی کند.
ترکیب نتایج تابع بیشینه هموار با بردار مقادیر
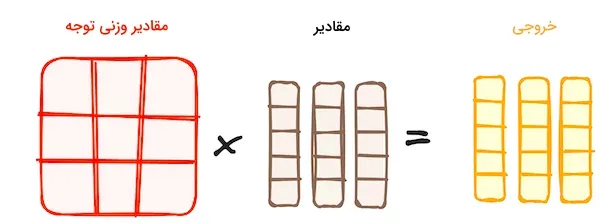
مقادیر وزنی حاصل از تابع بیشینه هموار با بردار مقادیر ضرب میشوند. این فرآیند باعث میشود که تنها کلماتی با امتیاز بالا حفظ شوند و بردار خروجی برای پردازش بیشتر به یک لایه خطی ارسال گردد.
مرحله ۲.۳ – نرمالسازی و اتصالهای باقیمانده
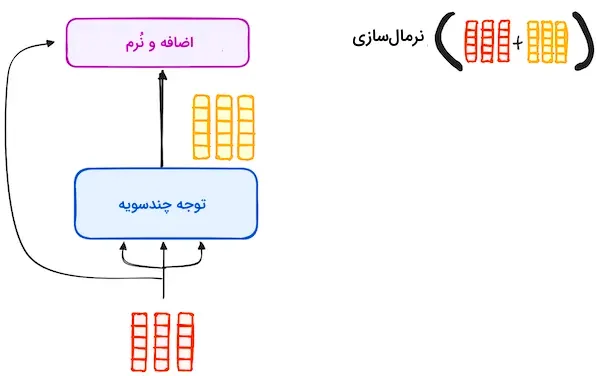
در هر زیرلایه از لایه رمزگذار، ابتدا یک مرحله نرمالسازی اجرا میشود. علاوه بر این، برای مقابله با مشکل «محوشدگی گرادیان»، خروجی هر زیرلایه به ورودی آن افزوده میشود. این فرآیند پس از عبور از شبکه عصبی پیشخور نیز تکرار میشود.
مرحله ۳.۳ – شبکه عصبی پیشخور
در این مرحله، خروجی نرمالشده از لایه رمزگذار وارد یک شبکه عصبی پیشخور «نقطهای» میشود. این شبکه شامل دو لایه خطی است که با استفاده از تابع فعالسازی ReLU خروجی تولید میکند. پس از آن، خروجی این شبکه با ورودی آن ترکیب شده و فرآیند تکمیل میشود. مشابه مراحل قبلی، در انتهای این مرحله نیز یک لایه نرمالسازی قرار میگیرد تا نتایج بهدستآمده با سایر خروجیها همراستا شود.
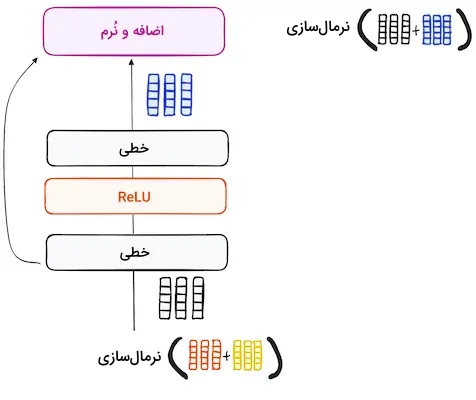
مرحله ۴ – خروجی رمزگذار
خروجی نهایی لایه رمزگذار مجموعهای از بردارها است که هر کدام حاوی بخشی از اطلاعات پردازششده تا این مرحله هستند. این خروجی بهعنوان ورودی به بخش رمزگشا وارد میشود. با استفاده از این مراحل در بخش رمزگذار، رمزگشا قادر میشود تا بر جنبههای مهم ورودی تمرکز کند.
این فرآیند را میتوان به ساخت یک برج تشبیه کرد که در آن چندین لایه رمزگذار بهطور متوالی بر هم قرار میگیرند و هر لایه جنبه خاصی از ورودی را استخراج میکند. این سلسلهمراتب نهتنها باعث درک چندوجهی از ورودی میشود، بلکه توان پیشبینی مدل ترنسفورمر را بهشدت تقویت میکند
ساختار رمزگشا
بخش رمزگشا در ترنسفورمر وظیفه تولید توالی متنی را بر عهده دارد و ساختاری مشابه رمزگذار دارد. بهطور خاص، رمزگشا شامل دو لایه توجه چندسویه، یک لایه پیشخور نقطهای و لایههای نرمالسازی پس از هر زیرلایه است.

در پایان فرایند رمزگشا، یک لایه خطی نقش «دستهبند» (Classifier) را ایفا میکند و با استفاده از یک تابع بیشینه هموار، احتمال وقوع کلمات مختلف را محاسبه مینماید. ساختار رمزگشا در مدلهای ترنسفورمر به گونهای طراحی شده است که خروجی را بهصورت مرحلهای تولید کند و اطلاعات رمزگذاریشده را رمزگشایی نماید.
نکته مهم در عملکرد رمزگشا این است که خودهمبسته است و از یک توکن آغاز میشود. این ساختار هوشمندانه از خروجیهای قبلی و خروجی رمزگذار بهعنوان ورودی استفاده میکند. در نهایت، رمزگشا با ایجاد یک توکن نشاندهنده پایان خروجی، فعالیت خود را خاتمه میدهد.
لایه های ساختار رمزگشا
مرحله ۱ – تعبیه خروجی
مانند فرآیند رمزگذار، در اینجا نیز ورودی ابتدا از یک لایه تعبیه شده عبور داده میشود.
مرحله ۲ – رمزگذاری موقعیتی
پس از آن، مشابه رمزگذار، ورودی به لایه رمزگذاری موقعیتی وارد میشود. این لایه، بردارهایی تولید میکند که موقعیت توکنها را دربردارند. سپس این بردارها به لایه توجه چندسویه فرستاده میشوند تا امتیاز توجه با دقت محاسبه گردد.
مرحله ۳ – پشته لایههای رمزگشا
رمزگشا از شش لایه انباشته تشکیل شده است و هر لایه شامل سه بخش است که در ادامه توضیح داده خواهند شد.
مرحله ۱.۳ – مکانیزم خودنگرش پوششی
این روش مشابه مکانیزم خودنگرش در رمزگذار است، اما با یک تفاوت اساسی. در ساختار رمزگشا، موقعیت هر توکن هیچ تاثیری بر موقعیت توکن بعدی ندارد و هر کلمه بهطور مستقل در نظر گرفته میشود. به عنوان مثال، کلمه “you” نباید در محاسبه امتیاز کلمه “are” نقشی داشته باشد.
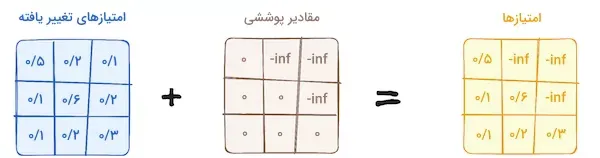
این فرآیند تضمین میکند که پیشبینیها در یک موقعیت خاص تنها به خروجیهای قبل از آن وابسته باشند.
مرحله ۲.۳ – توجه چندسویه رمزگذار-رمزگشا یا توجه متقابل
در دومین لایه توجه چندسویه، تعامل خاصی بین بخشهای مختلف رمزگذار و رمزگشا اتفاق میافتد. در این لایه، خروجی رمزگذار نقش کوئریها و همچنین کلیدها را ایفا میکند و مقادیر نیز از خروجی اولین لایه توجه رمزگشا بهدست میآید. بنابراین، نوع ورودی در رمزگذار و رمزگشا یکسان است و این امر به رمزگشا کمک میکند تا بخشهای مهم از ورودی رمزگذار را شناسایی کند.در ادامه، خروجی این لایه به یک لایه پیشخور نقطهای ارسال میشود تا پردازش بیشتری انجام گیرد.
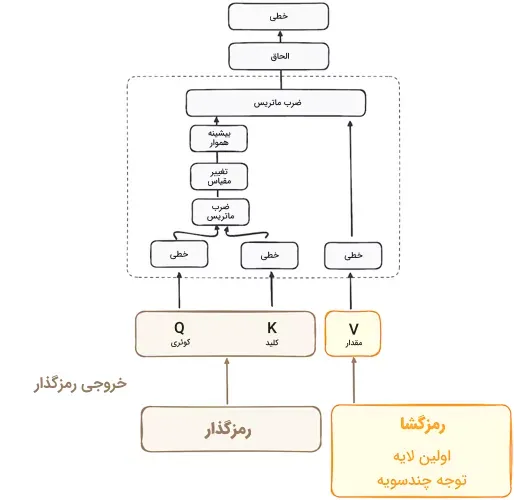
کوئریهای مربوط به این زیرلایه از رمزگشا و کلیدها و مقادیر از خروجی رمزگذار تامین میشوند. در این فرآیند، اطلاعات رمزگذار و رمزگشا با یکدیگر ترکیب میشوند.
مرحله ۳.۳ – شبکه عصبی پیشخور
مشابه رمزگذار، هر لایه رمزگشا شامل یک لایه تمام متصلی است که بهطور مستقل و یکسان بر هر توکن اعمال میشود.
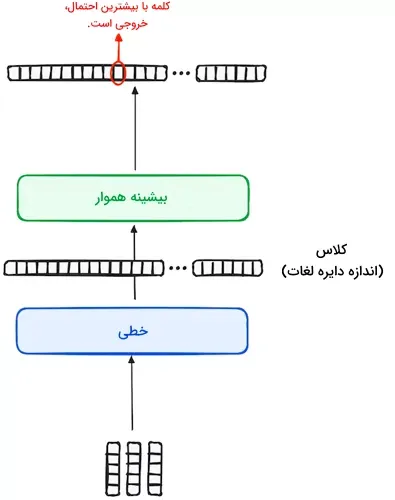
مرحله ۴ – دستهبند خطی و تابع بیشینه هموار برای تولید خروجی
فرآیند پردازش دادههای ورودی در مدل ترنسفورمر با عبور از یک لایه خطی که بهعنوان دستهبند عمل میکند، به پایان میرسد. اندازه این دستهبند برابر با تعداد کلاسهای مسئله یا تعداد کلمات موجود است. بهعنوان مثال، در یک مسئله با ۱۰۰۰ کلاس یا کلمه مختلف، خروجی دستهبند یک آرایه متشکل از ۱۰۰۰ نمونه خواهد بود. پس از آن، این خروجی وارد یک لایه بیشینه هموار میشود تا به برداری با دامنهای متغیر از ۰ تا ۱ تبدیل گردد. بالاترین احتمال در این بردار، همان کلیدی است که مدل پیشبینی میکند و بهعنوان کلمه بعدی در جمله مورد نظر خواهد بود.
نرمالسازی وخروجی رمزگشا
نرمالسازی و اتصالات باقیمانده
بعد از هر زیرلایه (همچون خودنگرش پوششی، توجه رمزگذار-رمزگشا، و شبکه پیشخور) یک مرحله نرمالسازی انجام میشود و خروجی هر لایه به ورودی لایه بعدی متصل میگردد.
خروجی رمزگشا
همانطور که پیشتر گفته شد، خروجی لایه نهایی رمزگشا یک دنباله است که از طریق یک لایه خطی و تابع بیشینه هموار، مجموعهای از احتمالات را برای پیشبینی کلمات تولید میکند. ساختار رمزگشا به گونهای است که خروجیهای جدید بهطور مداوم به لیست دادههای ورودی افزوده میشود و فرآیند رمزگشایی ادامه مییابد. این چرخه تکرار میشود تا زمانی که مدل ترنسفورمر، توکنی را به عنوان سیگنال پایان پیشبینی کند. توکن پایان معمولاً احتمال بالاتری نسبت به سایر توکنها دارد.
همچنین باید توجه داشت که رمزگشا تنها به یک لایه محدود نمیشود و میتواند از n لایه متوالی تشکیل شود که هر کدام ورودی خود را از بخش رمزگذار و لایههای قبلی دریافت میکنند. این معماری لایهای به مدل ترنسفورمر این امکان را میدهد که الگوها را با دقت بیشتر نسبت به سایر روشها شناسایی کند. ساختار نهایی ترنسفورمر به این صورت خواهد بود:
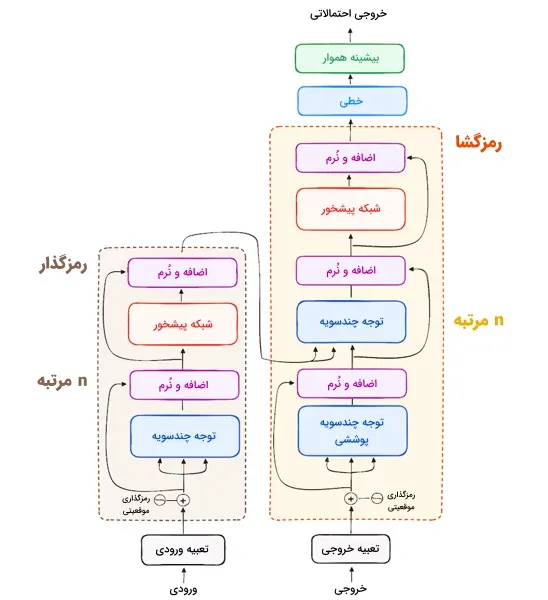
مدلهای ترنسفورمر کاربردی
پس از آشنایی با ساختار ترنسفورمر در یادگیری عمیق، در این بخش به معرفی مدلهای ترنسفورمری میپردازیم که توسط سازمانهای بزرگ توسعه یافته و در بسیاری از کاربردها مورد استفاده قرار گرفتهاند.
BERT
در سال ۲۰۱۸، شرکت گوگل با معرفی فریمورک پردازش زبان طبیعی و متنباز BERT، تحولی در زمینه NLP ایجاد کرد. قابلیت آموزش دو طرفه این فریمورک سبب شد تا مدلها قادر به پیشبینی دقیقتر کلمات بعدی در جملات شوند. BERT با درک محتوای دو طرف یک کلمه، عملکرد بهتری نسبت به مدلهای قبلی در کاربردهایی مانند پرسش و پاسخ و درک زبانهای مبهم از خود به نمایش گذاشت. فریمورک BERT برای اتصال عناصر ورودی و خروجی از ترنسفورمرها استفاده میکند.

به دلیل آموزش این مدل بر روی محتوای ویکیپدیا، BERT کاربرد گستردهای در مسائل مختلف NLP دارد و قرار است با موتور جستجوی گوگل برای نمایش دقیقتر نتایج کوئریها ادغام شود. این نوآوری را میتوان نقطه آغاز رقابت برای توسعه مدلهای پیشرفته زبانی دانست.
LaMDA
مدل LaMDA (مخفف Language Model for Dialogue Applications) که توسط شرکت گوگل در سال ۲۰۲۱ معرفی شد، یک مدل مبتنی بر ترنسفورمر است که بهطور ویژه برای کاربردهای مکالمهمحور طراحی شده است. هدف اصلی از توسعه این مدل تولید پاسخهای طبیعی و شبیه به زبان انسان بوده تا تجربه کاربری بهتری در نرمافزارهای مختلف ایجاد کند. LaMDA بهویژه برای بهبود مکالمات و تعاملات طبیعی در سیستمهای گفتگو و دستیارهای صوتی طراحی شده است.