آشنایی با مدلهای مختلف یادگیری ماشین و کاربردهای آنها
یادگیری ماشین (Machine Learning) یکی از زیرشاخههای مهم هوش مصنوعی است که به کامپیوترها امکان میدهد بدون نیاز به برنامهنویسی دستی، از دادهها و تجربیات خود بیاموزند. به طور خلاصه، یادگیری ماشین بخشی از هوش مصنوعی محسوب میشود. در نتیجه، هر مدل یادگیری ماشین را میتوان یک مدل هوشمند دانست، اما عکس این قضیه همیشه درست نیست. برخلاف روشهای سنتی که برای یادگیری از معادلات از پیش تعیین شده استفاده میکنند، مدلهای یادگیری ماشین به طور مستقیم و تنها از طریق دادههای ورودی آموزش میبینند و به مرور زمان بهبود مییابند.
برای آموزش هموش مصنوعی bia2ai مرجع تخصصی شماست.
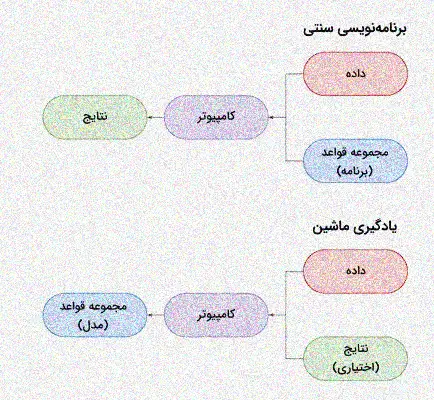
مدل در یادگیری ماشین به چه معناست؟
در یادگیری ماشین، مدل به یک الگوریتم اشاره دارد که پارامترهای آن از طریق یک فرآیند یادگیری آماری آموزش داده میشوند. به عبارت سادهتر، مدل یادگیری ماشین یک برنامه کامپیوتری است که میتواند وظایف خود را بدون نیاز به دستورالعملهای مستقیم انسانی انجام دهد. در روشهای برنامهنویسی سنتی، توسعهدهنده قوانینی را برای کامپیوتر تعریف میکند تا هنگام اجرا از آنها پیروی کند. اما در یادگیری ماشین، کامپیوتر از طریق اجرای یک الگوریتم یادگیری بر روی مجموعهای از دادهها (دیتاست)، بهطور خودکار مجموعهای از قوانین را ایجاد میکند. این مجموعه قوانین همان مدل یادگیری ماشین است که طی فرآیند آموزش به دست میآید.
یادگیری ماشین و مدلهای آن به این دلیل کارآمد هستند که پس از آموزش، بدون نیاز به راهنمایی بیشتر میتوانند از دانش خود برای حل مسائل مختلف بهره بگیرند. همچنین برخی مدلها که به آنها مدلهای مولد گفته میشود، قادرند دادههای جدیدی را تولید کنند. مدلهایی مانند DALL-E، Midjourney و Stable Diffusion از جمله این مدلهای پرطرفدار هستند که برای خلق تصاویر هنری و خلاقانه به کار میروند.
اهمیت انتخاب مدل مناسب در یادگیری ماشین
انتخاب مدل مناسب یکی از مراحل کلیدی در پروژههای یادگیری ماشین به شمار میرود. اما پیش از رسیدن به این مرحله، لازم است مفاهیم پایه و اساسی در یادگیری ماشین را به خوبی درک کنیم. مبانیای مانند روشهای کلاسیک، انواع الگوریتمهای یادگیری ماشین و اصول نظری که زیرساخت این حوزه را تشکیل میدهند، از جمله مواردی هستند که تسلط بر آنها ضروری است. داشتن دانش عمیق از این مبانی نه تنها برای انتخاب مدل مناسب اهمیت دارد، بلکه برای پیادهسازی موفق مدلها با استفاده از ابزارها و زبانهای برنامهنویسی مانند پایتون نیز الزامی است.
پس از کسب تسلط بر مفاهیم پایه، نوبت به انتخاب مدل مناسب برای هر مسئله یادگیری ماشین میرسد. اگر مدل به درستی انتخاب نشود، میتواند منجر به نتایج نامطلوب، کاهش عملکرد و حتی شکست پروژه شود. برای انتخاب صحیح مدل، باید عواملی مانند ماهیت مسئله، نوع و کیفیت دادهها، محدودیتهای موجود و معیارهای ارزیابی را در نظر گرفت. همچنین نیاز است که بین مدلهای مختلف یادگیری ماشین، مانند مدلهای خطی و غیرخطی، مدلهای ساده و پیچیده، تصمیمگیری کنید. این فرآیند به دانش تخصصی و تجربه کافی در حوزه یادگیری ماشین نیاز دارد.
چرا از مدلهای یادگیری ماشین استفاده میشود؟
امروزه بسیاری از سازمانها از مدلهای یادگیری ماشین برای افزایش درآمد و رشد کسبوکار خود بهره میگیرند. یادگیری ماشین به دلیل کاربردهای متنوعی که دارد، به یکی از ابزارهای ضروری در حوزههای مختلف تبدیل شده است. به عنوان مثال، سرویسهای اشتراکی مانند Netflix و Spotify از یادگیری ماشین برای پیشنهاد محتوا به کاربران بر اساس فعالیتهای قبلی آنها استفاده میکنند. از آنجایی که بهبود تجربه کاربری یکی از عوامل کلیدی در ترغیب کاربران به تمدید اشتراک است، استفاده از سیستمهای توصیهگر باعث افزایش ارزش این کسبوکارها میشود.
به طور مشابه، سرویسدهندگان خدمات تلفن همراه ممکن است از یادگیری ماشین برای تجزیه و تحلیل بازخورد کاربران استفاده کنند تا خدمات خود را به گونهای بهینه کنند که با نیازهای بازار هماهنگ باشد. این قابلیت به شرکتها اجازه میدهد تا تصمیمات بهتری بگیرند و در نهایت به افزایش رضایت مشتری و رشد پایدار دست یابند.
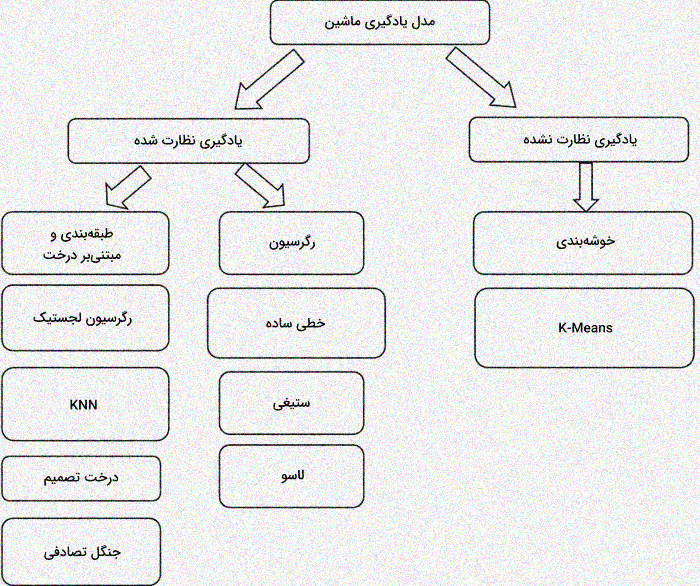
انواع مدلهای یادگیری ماشین
مدلهای یادگیری ماشین به طور کلی به دو دسته اصلی «نظارت شده» و «نظارت نشده» تقسیم میشوند. تفاوت اصلی میان این دو دسته در نوع دادههایی است که برای آموزش استفاده میشود. در مدلهای نظارت شده، از دادههای برچسبدار استفاده میشود، به این معنا که هر داده ورودی با خروجی مشخصی همراه است. در مقابل، مدلهای نظارت نشده از دادههای بدون برچسب یا دادههای خام برای یادگیری استفاده میکنند.
در ادامه، به معرفی چند نوع از این مدلها میپردازیم:
مدلهای نظارت شده:
- رگرسیون: برای پیشبینی مقادیر پیوسته مانند قیمت خانه یا دمای هوا استفاده میشود.
- طبقهبندی: برای دستهبندی دادهها در گروههای مشخص، مانند شناسایی ایمیلهای اسپم یا غیر اسپم به کار میرود.
- مدلهای مبتنی بر درخت: مانند درخت تصمیمگیری که برای انجام پیشبینیهای دقیق و تفسیرپذیر استفاده میشود.
مدلهای نظارت نشده:
- خوشهبندی: برای گروهبندی دادههای مشابه بدون برچسب به کار میرود، مانند دستهبندی مشتریان بر اساس رفتار خرید آنها.
این دستهبندی به متخصصان یادگیری ماشین کمک میکند تا براساس نوع داده و هدف پروژه، مدل مناسب را انتخاب کنند.
مدلهای رگرسیون
الگوریتمهای رگرسیونی برای پیشبینی مقادیر پیوسته از متغیرهای ورودی مستقل به کار میروند. به عنوان نمونه، به جدول ارائه شده در تصویر دقت کنید:
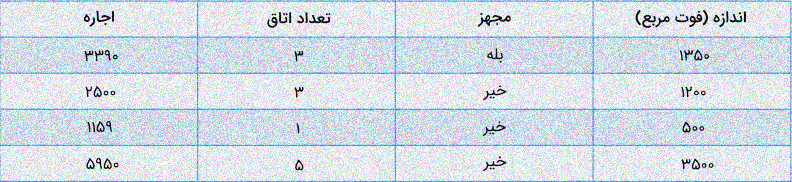
در این مثال، هدف پیشبینی اجارهخانه بر اساس اندازه (به فوت مربع)، تعداد اتاقها و مجهز بودن یا نبودن خانه است. از آنجا که مقدار اجارهخانه به صورت عددی و پیوسته است، این مسئله در دسته مسائل رگرسیونی قرار میگیرد.
به طور دقیقتر، زمانی که تعداد زیادی متغیر ورودی وجود دارد، از رگرسیون چندمتغیره استفاده میشود تا رابطه بین ویژگیهای مختلف و متغیر وابسته به درستی مدلسازی شده و پیشبینی دقیقتری حاصل شود.