

آشنایی با ماشین بردار پشتیبان (SVM) – الگوریتمی کاربردی
در میان الگوریتمهای یادگیری ماشین، بیشتر افراد یادگیری را با رگرسیون آغاز میکنند. این الگوریتم به دلیل سادگی، یادگیری آن آسان است. با این حال، بسیاری از مسائل تنها با رگرسیون قابل حل نیستند. در چنین شرایطی، از الگوریتمهای دیگری مانند ماشین بردار پشتیبان (Support Vector Machine | SVM) استفاده میشود.
الگوریتم SVM یکی از مؤثرترین روشهای یادگیری ماشین است که در مسائل خطی و غیرخطی کاربرد دارد. این الگوریتم طیف گستردهای از مسائل را پوشش میدهد و در مواردی مانند شناسایی سرطان تا زمینشناسی مورد استفاده قرار میگیرد.
در این مقاله، با تعریف ماشین بردار پشتیبان آشنا میشویم. تفاوتهای آن با رگرسیون لجستیک بررسی میشود. انواع مختلف این الگوریتم و نحوه عملکرد آن توضیح داده میشود.یک مثال کاربردی از پیادهسازی آن ارائه میشود.در پایان نیز به کاربردهای مهم الگوریتم SVM در یادگیری ماشین پرداخته و مزایا و معایب آن مورد بررسی قرار میگیرند.

آشنایی با الگوریتم ماشین بردار پشتیبان (SVM)
ماشین بردار پشتیبان (SVM) یکی از الگوریتمهای نظارتشده در یادگیری ماشین است که برای حل مسائل طبقهبندی و رگرسیون مورد استفاده قرار میگیرد. این الگوریتم بهویژه در مسائل طبقهبندی دودویی که دادههای دیتاست باید به دو گروه مجزا تقسیم شوند، کاربرد دارد.
هدف اصلی الگوریتم SVM یافتن بهترین خط یا مرز تصمیمگیری است که نقاط داده را بر اساس گروه یا کلاس آنها از یکدیگر جدا کند. این مرز، که در فضاهای با ویژگیهای زیاد ابَرصفحه (Hyperplane) نامیده میشود، باید طوری انتخاب شود که فاصله یا حاشیه میان ابرصفحه و نزدیکترین نقاط داده از هر کلاس بیشترین مقدار ممکن باشد؛ چرا که حاشیه بزرگتر نشاندهنده دستهبندی دقیقتر است.
تفاوتهای رگرسیون لجستیک و ماشین بردار پشتیبان (SVM)
انتخاب بین رگرسیون لجستیک و ماشین بردار پشتیبان (SVM) به ویژگیهای دیتاست و نوع مسئله بستگی دارد. الگوریتم SVM بهطور خاص زمانی بیشترین کارایی را نشان میدهد که با دیتاستهای کوچک و پیچیده مواجه باشید. معمولاً فرآیند کار به این صورت است که ابتدا رگرسیون لجستیک آزمایش میشود و اگر دقت لازم حاصل نشود، از SVM استفاده میشود.
هرچند هر دو الگوریتم در یادگیری نظارتشده عملکرد مشابهی دارند، اما ویژگیهای خاص دیتاست میتواند تعیین کند کدام یک نتایج بهتری ارائه میدهد. رگرسیون لجستیک بیشتر برای مسائل طبقهبندی دودویی مناسب است و عملکرد سادهای دارد. از سوی دیگر، SVM در طبقهبندی دادههای خطی و غیرخطی، مقابله با مشکل بیشبرازش و کار در فضاهای با ابعاد بالا، قابلیتهای برتری ارائه میدهد.
یادگیری نظارتشده یکی از شاخههای مهم یادگیری ماشین است که الگوریتمها با استفاده از دادههای برچسب دار آموزش میبینند. این روش در مسائلی مانند تشخیص تصویر، پیشبینی قیمتها و تشخیص ایمیلهای اسپم کاربرد گستردهای دارد.
ماشین بردار پشتیبان به دلیل توانایی در ایجاد دستهبندی دقیق در دادههای پیچیده و عملکرد عالی در فضاهای پر از ویژگی، از اهمیت زیادی برخوردار است. در مقابل، رگرسیون لجستیک الگوریتمی سادهتر اما مؤثر برای حل مسائل طبقهبندی دودویی به شمار میرود. انتخاب نهایی میان این دو به دادههای موجود و نیاز مسئله بستگی دارد.
انواع الگوریتم ماشین بردار پشتیبان (SVM)
تا اینجا یاد گرفتیم که ماشین بردار پشتیبان (SVM) چیست و چه تفاوتی با الگوریتم رگرسیون لجستیک دارد. حالا با توجه به مرز تصمیم، الگوریتم SVM را میتوان به دو نوع زیر تقسیم کرد:
1.خطی
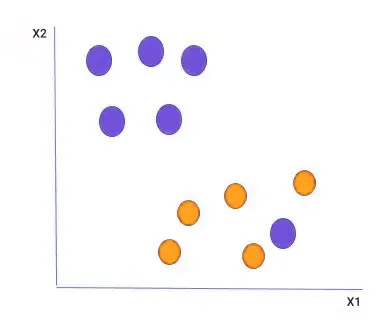
در این نوع از الگوریتم SVM، از یک مرز تصمیمگیری خطی برای جدا کردن نقاط داده کلاسهای مختلف از یکدیگر استفاده میشود. این الگوریتم زمانی کاربرد دارد که دادهها بهطور خطی قابل جداسازی باشند. به بیان سادهتر، باید بتوان با تنها یک خط راست در فضای ۲ یا چند بعدی، دادهها را در کلاسهای مجزای خود طبقهبندی کرد. ابَرصفحه (Hyperplane) که فاصله میان کلاسها را به حداکثر میرساند، همان مرز تصمیم است.
2.غیر خطی
زمانی از نوع غیرخطی الگوریتم SVM استفاده میشود که نتوانیم دادهها را با یک خط راست به دو کلاس مختلف تقسیم کنیم. در این حالت، ابتدا دادههای ورودی از طریق توابعی به نام توابع کرنل (Kernel Functions) به فضایی با ابعاد بالاتر نگاشت میشوند و سپس بهطور خطی از هم جدا میشوند. برای ایجاد مرز تصمیمگیری غیرخطی در این فضای ویژگی تغییر یافته، از یک SVM خطی استفاده میشود.
حالا که با ماشین بردار پشتیبان و انواع آن آشنا شدیم، در ادامه با روش کارکرد این الگوریتم مهم در یادگیری ماشین آشنا میشویم.
نحوه عملکرد الگوریتم ماشین بردار پشتیبان (SVM)
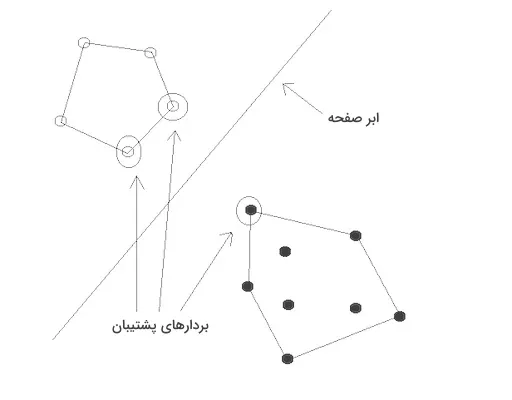
در الگوریتم ماشین بردار پشتیبان (SVM)، برای تعیین مرز جداسازی، تنها نزدیکترین نقاط داده یا همان بردارهای پشتیبان به ابرصفحه اهمیت دارند. برخلاف رگرسیون لجستیک که برای تعیین دستهبند به تمام نقاط داده نیاز دارد، در SVM تنها نقاط نزدیک به مرز تصمیمگیری مورد توجه قرار میگیرند. یک راهحل منطقی برای تعیین این مرز، انتخاب ابرصفحهای است که بیشترین جدایی یا حاشیه را میان دو کلاس ایجاد کند.
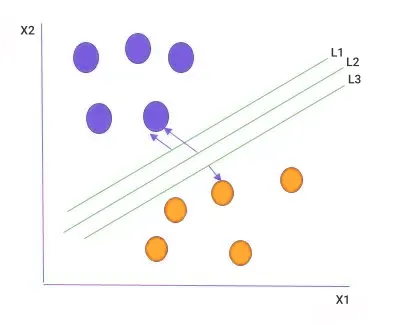
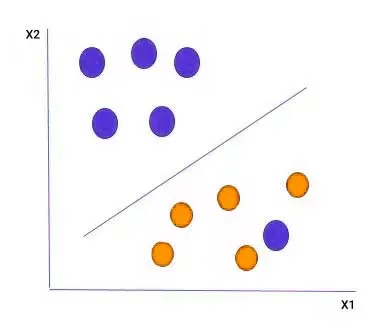
در صورتی که نمونههای پرت در دادهها وجود داشته باشد، الگوریتم SVM همچنان مرز تصمیمگیری با بیشترین حاشیه را پیدا کرده و در صورتی که نمونهای از این حاشیه عبور کند، مقدار جریمهای به ابرصفحه اضافه میکند. به این نوع ابرصفحه، حاشیه نرم (Soft Margin) گفته میشود.اما در برخی مواقع، دادهها نمیتوانند بهصورت خطی از هم جدا شوند.
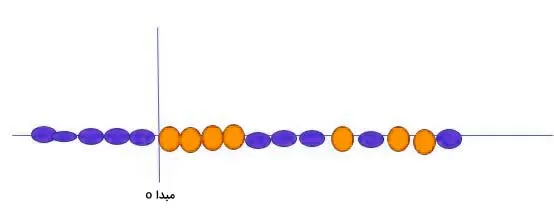
در چنین شرایطی، راهحل الگوریتم SVM استفاده از یک کرنل برای ساخت یک متغیر جدید است. به این صورت که نقطهای (xᵢ) روی محور افقی انتخاب کرده و متناظر با آن، متغیر دیگری بهعنوان تابع فاصله (yᵢ) از مبدا تعریف میکنیم. با رسم مجموعه دادهها و ابرصفحه، به تصویری مشابه آنچه در تصویر زیر مشاهده میشود، دست پیدا خواهیم کرد.
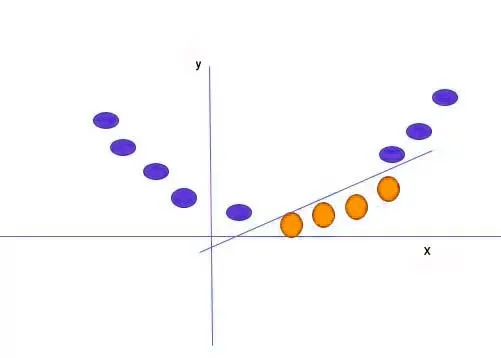
این تابع غیرخطی yᵢ بهعنوان کرنل شناخته میشود.
مفاهیم رایج در الگوریتم ماشین بردار پشتیبان (SVM)
در بررسی الگوریتم ماشین بردار پشتیبان (SVM)، مفاهیم و عباراتی وجود دارند که ممکن است در ابتدا بهطور کامل قابل درک نباشند. در اینجا به معرفی و توضیح چند مورد از این مفاهیم پرداختهایم:
1.ابر صفحه (Hyperplane):مرز تصمیمگیری است که برای جدا کردن نمونههای مختلف از هم در فضای ویژگی استفاده میشود. در طبقهبندی خطی، ابرصفحه معادلهای به شکل wx + b = 0 است.
2.بردارهای پشتیبان (Support Vectors):نزدیکترین نقاط داده به ابرصفحه هستند که نقش کلیدی در تعیین حاشیه و ابرصفحه دارند.
3.حاشیه (Margin): فاصله میان بردار پشتیبان و ابرصفحه است. هدف الگوریتم SVM بیشینهسازی این حاشیه است. حاشیه بیشتر نشاندهنده عملکرد بهتر در طبقهبندی است.
4.کرنل (Kernel): تابع ریاضیاتی است که در الگوریتم SVM برای نگاشت دادهها به فضای ویژگی با ابعاد بالاتر استفاده میشود. این امکان را فراهم میکند که حتی اگر دادهها خطی قابل جداسازی نباشند، بتوان مرز تصمیم یا ابرصفحه را بهراحتی پیدا کرد. برخی از رایجترین کرنلها عبارتاند از: خطی، چند جملهای، تابع شعاعی پایه (RBF) و سیگوئید.
5.حاشیه سخت (Hard Margin): ابر صفحهای که تمام نقاط داده را بدون خطا در کلاسهای جدا از هم دستهبندی میکند.
6.حاشیه نرم (Soft Margin): زمانی که دادهها بهطور کامل قابل جداسازی نیستند یا شامل نمونههای پرت هستند، SVM از حاشیه نرم استفاده میکند. در این روش برای هر نقطه داده، یک متغیر در نظر گرفته شده و بسته به مقدار آن، الگوریتم امکان نادیده گرفتن برخی نمونههای پرت یا قواعد را فراهم میکند. این بهعبارت دیگر یک مصالحه است که در آن از یک طرف حاشیه افزایش مییابد و از طرف دیگر، پایبندی به طبقهبندی دقیق کاهش مییابد.
پیادهسازی الگوریتم ماشین بردار پشتیبان در پایتون
برای درک بهتر عملکرد الگوریتم ماشین بردار پشتیبان (SVM) و نحوه عملکرد آن، در این بخش از مقاله، با استفاده از زبان برنامهنویسی پایتون و دیتاست سرطان از کتابخانه Scikit-learn به تشخیص نوع خوشخیم یا بدخیم بیماری میپردازیم. دادههای تاریخی بیماران مبتلا به سرطان به پزشکان کمک میکند تا انواع خوشخیم و بدخیم بیماری را تشخیص دهند. در اینجا مراحل پیادهسازی الگوریتم SVM را بررسی خواهیم کرد:
مرحله 1: بارگذاری کتابخانههای مورد نیاز
ابتدا، کتابخانههایی که برای اجرای الگوریتم SVM و رسم نمودار نیاز داریم، بارگذاری میکنیم:
# Load the important packages
from sklearn.datasets import load_breast_cancer
import matplotlib.pyplot as plt
from sklearn.inspection import DecisionBoundaryDisplay
from sklearn.svm import SVC
مرحله 2: بارگذاری دیتاست سرطان
در این مرحله، دیتاست بیماری سرطان را در متغیری به نام cancer بارگذاری کرده و دو متغیر X و y را که به ترتیب ویژگیها (دو ستون اول) و کلاس هدف دیتاست را نشان میدهند، ذخیره میکنیم:
# Load the datasets
cancer = load_breast_cancer()
X = cancer.data[:, :2]
y = cancer.target
مرحله 3: ساخت و آموزش دستهبند SVM
در این مرحله، مدل یا دستهبند SVM را با استفاده از کلاس SVC و پارامتر کرنل rbf ساخته و مدل را با متد fit() آموزش میدهیم:
#Build the model
svm = SVC(kernel="rbf", gamma=0.5, C=1.0)
# Trained the model
svm.fit(X, y)
مرحله 4: رسم فضای ویژگی و مرز تصمیم
در این مرحله، با استفاده از مدل آموزشدیده، عملکرد الگوریتم SVM را به تصویر میکشیم. از دو ویژگی اول دیتاست، یعنی mean radius و mean texture، برای رسم نمودار استفاده میکنیم:
# Plot Decision Boundary
DecisionBoundaryDisplay.from_estimator(
svm,
X,
response_method="predict",
cmap=plt.cm.Spectral,
alpha=0.8,
xlabel=cancer.feature_names[0],
ylabel=cancer.feature_names[1],
)
# Scatter plot
plt.scatter(X[:, 0], X[:, 1],
c=y,
s=20, edgecolors="k")
plt.show()
خروجی به صورت زیر است:
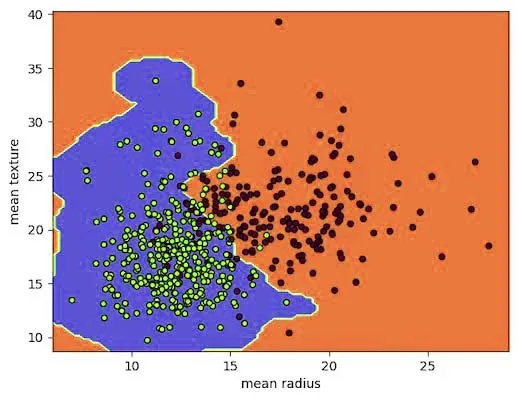
در نمودار بالا، بهوضوح مشاهده میکنید که الگوریتم SVM با وجود نمونههای پرت در هر دو کلاس، بهخوبی قادر به جدا کردن دو کلاس مختلف است. در اینجا، مرز تصمیم به وضوح نمایش داده میشود که بهکمک آن، الگوریتم نقاط داده را از یکدیگر تفکیک میکند.
حالا که با نحوه پیادهسازی الگوریتم SVM آشنا شدیم، در بخش بعدی به برخی از کاربردهای این الگوریتم در دنیای واقعی خواهیم پرداخت.
کاربردهای ماشین بردار پشتیبان (SVM)
الگوریتم ماشین بردار پشتیبان (SVM) برای دستهبندی دادهها از روشهای یادگیری نظارتشده در یادگیری ماشین بهره میبرد. یادگیری ماشین امروزه به یکی از تأثیرگذارترین حوزههای فناوری تبدیل شده است و در صنایع مختلف از پزشکی و مراقبتهای بهداشتی گرفته تا مالی، خودروسازی و کشاورزی نقش اساسی ایفا میکند.
الگوریتم ماشین بردار پشتیبان (SVM) یکی از الگوریتمهای برجسته در این حوزه است که به دلیل دقت بالا و توانایی حل مسائل پیچیده طبقهبندی و رگرسیون، در کاربردهای عملی فراوانی مورد استفاده قرار میگیرد. برای موفقیت در یادگیری ماشین، آشنایی با مجموعهای از الگوریتمها و تکنیکهای مختلف ضروری است. آموزش مفاهیم پایه و پیشرفته این حوزه نه تنها برای پیشرفت فردی بلکه برای نوآوری و توسعه در صنایع مختلف اهمیت زیادی دارد.در ادامه به برخی از این کاربردها میپردازیم.
1.مسائل زمینشناسی
یکی از کاربردهای برجسته الگوریتم ماشین بردار پشتیبان در زمینشناسی است، جایی که از این الگوریتم برای پایش ساختار لایهای زمین استفاده میشود. این نوع مسائل که «وارونگی» (Inversion) نامیده میشوند، زمانی پیش میآید که مشاهدات بهدست آمده به پارامترهای مولد خود وابسته باشند. در این فرآیند، مدلهای خطی و الگوریتم SVM به جداسازی دادههای الکترومغناطیسی کمک میکنند. هرچه ابعاد مسئله کوچکتر باشد، پیچیدگی کمتری نیز در تحلیل دادهها وجود خواهد داشت.
2. ارزیابی احتمال روانگرایی
در هنگام وقوع رخدادهایی مانند زلزله، مسئله «روانگرایی خاک» (Soil liquefaction) از اهمیت ویژهای برخوردار است. این موضوع باید در طراحی و ساخت هر نوع زیرساخت عمرانی مورد توجه قرار گیرد. الگوریتم SVM در تشخیص احتمال رخداد جنبههای مختلف روانگرایی نقش کلیدی دارد. در این فرآیند، آزمایشهای «نفوذ استاندارد» (Standard Penetration Test | SPT) و «نفوذ مخروط» (Cone Penetration Test | CPT) با استفاده از SVM پیادهسازی میشوند و از دادههای محیطی برای پیشبینی وقوع زمینلرزه بهره برداری میشود.
علاوه بر این، الگوریتم SVM در توسعه مدلهایی که شامل چند متغیر مانند معیارهای خاک و پارامترهای روانگرایی هستند، برای تعیین نیروی سطح زمین نیز کاربرد دارد. دقت الگوریتم ماشین بردار پشتیبان در این مسائل به حدود ۹۶ تا ۹۷ درصد میرسد.
3. بازشناسی همولوژی از راه دور پروتئین
همولوژی از راه دور پروتئین شاخهای از زیستشناسی محاسباتی است که در آن پروتئینها بر اساس دنباله آمینو اسیدها به پارامترهای ساختاری و کاربردی تقسیم میشوند. الگوریتم SVM به شناسایی دنبالههای پروتئینی مشابه کمک میکند و نقش حیاتی در بازشناسی همولوژی از راه دور و پیشرفتهای زیستشناسی محاسباتی ایفا میکند.
4. دستهبندی داده
الگوریتم ماشین بردار پشتیبان یا SVM در یادگیری ماشین بهعنوان راهحلی برای مسائل پیچیده ریاضی شناخته میشود. بهویژه نوعی از SVM برای «دستهبندی داده» بسیار مناسب است، چرا که با کاهش تعداد نمونههای پرت و شناسایی الگوها، عملکرد بهتری در طبقهبندی دادهها ارائه میدهد.
5.تشخیص چهره و طبقهبندی احساسات با الگوریتم SVM
الگوریتم ماشین بردار پشتیبان (SVM) در پردازش تصاویر برای تشخیص ساختار چهرهها بسیار مؤثر است. در این فرایند، مجموعه دادهای آموزشی شامل دو کلاس مختلف (چهره با برچسب ۱+ و غیرچهره با برچسب ۱-) به همراه تصاویری با ابعاد n×n پیکسل برای تمایز تصاویر چهره از غیرچهره استفاده میشود. پس از تجزیه و تحلیل هر پیکسل، ویژگیهای مربوط به چهره استخراج میگردد. سپس با توجه به شدت پیکسلها، مرز تصمیمگیری برای تشخیص و دستهبندی تصاویر به دور ساختار چهره ترسیم میشود. علاوهبر این، SVM در طبقهبندی احساسات چهره نیز کاربرد دارد و میتواند احساسات مختلف افراد را شناسایی کند.

6.دستهبندی بافت سطح با الگوریتم SVM
برای دستهبندی تصاویر مرتبط با سطوح مختلف، از الگوریتم ماشین بردار پشتیبان (SVM) استفاده میشود. در این فرایند، با توجه به تصاویر ثبتشده، الگوریتم SVM بافت سطوح مختلف را به کلاسهای مختلفی همچون “صاف” و “ناهموار” تقسیم میکند. این الگوریتم توانایی شناسایی ویژگیهای خاص هر سطح و تفکیک آنها بر اساس تفاوتهای موجود در بافت را دارد.
7.طبقهبندی متن و بازشناسی دستخط با الگوریتم SVM
طبقهبندی متن فرآیندی است که در آن دادههای متنی به دستههای از پیش تعریف شده تقسیم میشوند. بهعنوان مثال، مقالات خبری میتوانند به دستههای مختلفی مانند سیاست، کسبوکار، ورزش و اقتصاد تقسیم شوند، یا ایمیلها به دو گروه «عادی» و «اسپم» دستهبندی شوند. در این فرآیند، به هر مقاله یا محتوای متنی امتیاز خاصی اختصاص مییابد و سپس، با مقایسه این امتیاز با حد آستانهای مشخص، آن محتوا در دسته مربوطه قرار میگیرد.
در زمینه بازشناسی دستخط، ورودی الگوریتم SVM دیتاستی است که شامل دستنوشتههای افراد مختلف است. معمولاً، آموزش دستهبندهای SVM ابتدا با تعداد کمی از دادهها آغاز میشود و سپس با استفاده از امتیازهای بهدست آمده، فرآیند طبقهبندی ادامه مییابد. علاوهبر این، الگوریتم SVM برای تشخیص متون نوشتهشده توسط انسان از متونی که توسط کامپیوتر تولید شدهاند نیز کاربرد دارد.
8.بازشناسی گفتار با الگوریتم SVM
در بازشناسی گفتار، کلمات از صدا جدا شده و ویژگیهای خاص هر کلمه استخراج میشود. برای این کار از تکنیکهایی مثل LPC، MFCC و LPCC استفاده میشود که ویژگیهای صوتی را جمعآوری کرده و سپس به الگوریتم SVM برای شناسایی و پردازش دادهها وارد میکنند. این روش به دقت بیشتری در تبدیل گفتار به متن کمک میکند.
9.شناسایی تغییر در تصاویر با الگوریتم SVM
الگوریتم SVM قادر است تغییرات و دستکاریهای صورت گرفته در تصاویر دیجیتال را شناسایی کند. این روش در کاربردهای امنیتی که تصاویر ممکن است آلوده یا تغییر کرده باشند، بسیار مفید است. معمولاً تراکم پیکسلها در این تصاویر بالا است و پیدا کردن پیامهای مخفی دشوار است. با این حال، با جداسازی پیکسلها و ذخیرهسازی دادهها در دیتاستهای مجزا برای مدل SVM، میتوان این تصاویر را به دقت بررسی و تحلیل کرد.
10.تشخیص سرطان با الگوریتم SVM
برای سالها، متخصصان پزشکی و پژوهشگران در جستجوی روشی برای تشخیص سرطان در مراحل اولیه بودهاند. امروزه ابزارهای هوش مصنوعی و یادگیری ماشین به کمک آمدهاند. به عنوان نمونه، در ژانویه ۲۰۲۰، شرکت گوگل ابزاری هوشمند برای تشخیص سرطان سینه معرفی کرد. در این فرآیند، تصاویر سلولهای سرطانی به عنوان ورودی به مدل SVM وارد شده و پس از تحلیل و آموزش، سلولها به دو گروه خوشخیم و بدخیم تقسیم میشوند.

مزایا و معایب ماشین بردار پشتیبان (SVM)
ماشین بردار پشتیبان (SVM) یکی از الگوریتمهای مهم در یادگیری ماشین است که به دلیل کاربردهای وسیع خود مزایا و معایب خاصی دارد. برای استفاده بهینه از این الگوریتم، درک مزایا و معایب آن بسیار ضروری است.

مزایا:
- کارایی بالا برای دادههای خطی: الگوریتم SVM در صورتی که دادهها بهصورت خطی قابل تفکیک باشند، عملکرد بسیار خوبی دارد.
- عملکرد بهتر در ابعاد بالا: SVM میتواند بهخوبی با دادههای با ابعاد بالا کار کند، که آن را برای مسائل پیچیده مناسب میسازد.
- توانایی حل مسائل پیچیده: با استفاده از توابع کرنل، SVM قادر به حل مسائل پیچیده و غیرخطی است.
مقاومت در برابر - نمونههای پرت: SVM به دلیل ساختار خاص خود در برابر دادههای نویزی و پرت مقاوم است.
کارآمد در دستهبندی تصاویر: این الگوریتم بهویژه در مسائل مربوط به دستهبندی تصاویر مؤثر است.
معایب:
- انتخاب تابع کرنل مناسب: انتخاب تابع کرنل مناسب برای مسائل مختلف میتواند چالشبرانگیز باشد.
- عملکرد ضعیف در دیتاستهای بزرگ: در هنگام کار با دیتاستهای بسیار بزرگ، SVM ممکن است از نظر عملکرد با مشکلاتی مواجه شود.
- پیچیدگی در تنظیم و تفسیر نتایج: تنظیم پارامترهای الگوریتم و بهتصویر کشیدن نتایج میتواند پیچیده و زمانبر باشد.