
دادههای نامتوازن و ۷ تکنیک مدیریت آنها
در بسیاری از مسائل مرتبط با دادهکاوی و یادگیری ماشین، با پدیدهای به نام دادههای نامتوازن (Imbalanced Data) مواجه میشویم. این نوع دادهها در صنایعی مانند بانکداری، بازاریابی آنلاین و پزشکی به وفور یافت میشوند. به عنوان مثال، در بررسی تراکنشهای بانکی، معمولاً درصد کمی از کل تراکنشها مشکوک به تقلب هستند. این شرایط، چالشهایی جدی را برای یادگیری ماشین و الگوریتمهای دستهبندی ایجاد میکند.
در این مقاله، ابتدا مفهوم دادههای نامتوازن و چالشهای مدیریت آنها را توضیح میدهیم. سپس، اهمیت مدیریت این دادهها را بررسی کرده و در نهایت ۷ تکنیک مؤثر برای مدیریت دادههای نامتوازن را معرفی میکنیم.
مفهوم دادههای نامتوازن
دادههای نامتوازن به مجموعهدادههایی گفته میشود که توزیع کلاسهای هدف به صورت نابرابر است. به عبارت دیگر، در حالی که یک کلاس تعداد زیادی نمونه دارد (کلاس اکثریت)، کلاس دیگر با کمبود نمونه مواجه است (کلاس اقلیت).
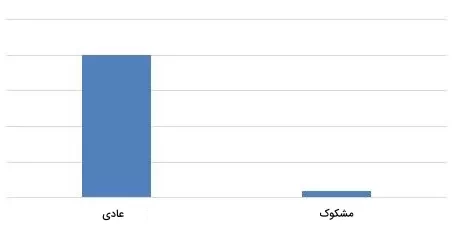
مثال: تراکنشهای بانکی فرض کنید یک بانک قصد دارد تراکنشهای مشکوک به تقلب را شناسایی کند. در میان ۲۰۰۰ تراکنش، تنها ۳۰ مورد مشکوک هستند. این یعنی کمتر از ۲ درصد دادهها مربوط به کلاس اقلیت است. در چنین مواردی، دادههای کلاس اکثریت (عادی) میتوانند به طور قابلتوجهی بر یادگیری مدل تسلط پیدا کنند و منجر به سوگیری شوند.
چالشهای مدیریت دادههای نامتوازن
دادههای نامتوازن میتوانند دقت پیشبینی مدلهای یادگیری ماشین را تحت تأثیر قرار دهند. در ادامه برخی از چالشهای اصلی مرتبط با این نوع دادهها آورده شده است:
- سوگیری مدل به سمت کلاس اکثریت
مدلها تمایل دارند دادههای کلاس اکثریت را به درستی پیشبینی کنند، اما در شناسایی نمونههای کلاس اقلیت با مشکل مواجه میشوند. - مشکلات معیارهای سنتی ارزیابی
معیارهایی مانند دقت (Accuracy) ممکن است در چنین شرایطی گمراهکننده باشند. به عنوان مثال، اگر یک مدل تمام نمونهها را به کلاس اکثریت اختصاص دهد، دقت بالایی خواهد داشت، اما عملکرد آن عملاً مطلوب نیست. - قابلیت تعمیمپذیری ضعیف
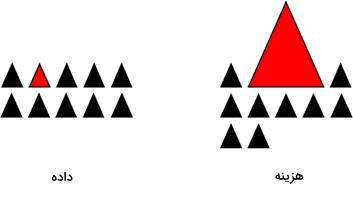
به دلیل کمبود دادههای کلاس اقلیت در فرایند آموزش، مدل ممکن است در پیشبینی دادههای جدید عملکرد ضعیفی داشته باشد. - هزینههای بالا در طبقهبندی اشتباه
در مسائل حساس مانند تشخیص بیماری، خطا در شناسایی کلاس اقلیت (افراد بیمار) میتواند عواقب جدی و پرهزینهای به همراه داشته باشد. - معیارهای ارزیابی گمراهکننده
برای دادههای نامتوازن، استفاده از معیارهایی مانند F1-Score و سطح زیر نمودار ROC (AUC) مناسبتر است.
چرا باید به دادههای نامتوازن رسیدگی کنیم؟
رسیدگی به دادههای نامتوازن ضروری است زیرا:
- عملکرد مدلهای یادگیری ماشین در پیشبینی کلاس اقلیت بهبود مییابد.
- هزینههای مرتبط با خطاهای طبقهبندی کاهش مییابد.
- تعادل بین دقت پیشبینی کلاسهای مختلف حفظ میشود.

تکنیکهای مدیریت دادههای نامتوازن
برای مقابله با چالشهای دادههای نامتوازن، تکنیکهای مختلفی وجود دارد. در ادامه ۷ روش متداول برای مدیریت این نوع دادهها توضیح داده میشود: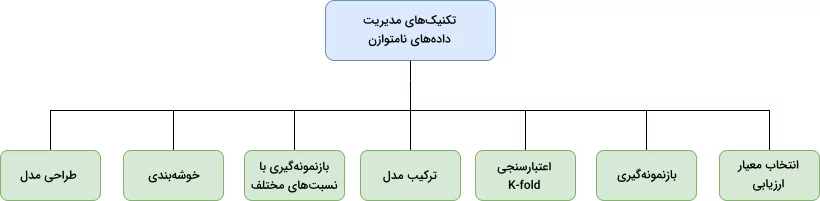
1. انتخاب معیار ارزیابی مناسب
انتخاب معیار ارزیابی مناسب اولین قدم برای مدیریت دادههای نامتوازن است. معیارهایی مانند دقت (Precision) و بازیابی (Recall) به ترتیب به دقت پیشبینی یک کلاس خاص و توانایی مدل در شناسایی آن کلاس اشاره دارند. معیار F1-Score نیز که میانگین همساز دقت و بازیابی است، یکی از مناسبترین گزینهها برای ارزیابی مدلها در شرایط نامتوازن محسوب میشود.
فرمول F1-Score به صورت زیر است:
این معیار زمانی افزایش مییابد که تعداد و کیفیت پیشبینیهای درست بهبود یابد.
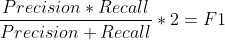
2. بازنمونهگیری از مجموعه آموزشی
برای متوازنسازی دادهها میتوان از دو روش بازنمونهگیری استفاده کرد:
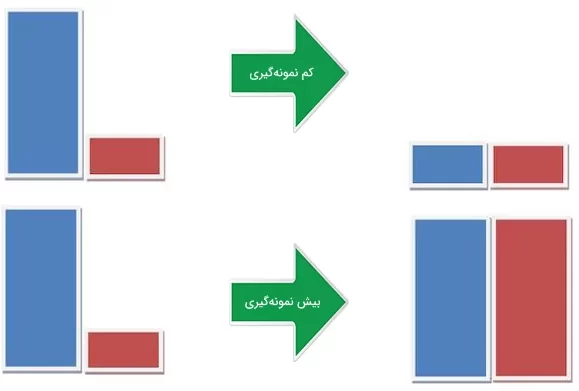
کمنمونهگیری (Undersampling): در این روش، تعداد نمونههای کلاس اکثریت کاهش مییابد تا توزیع کلاسها متوازن شود.
بیشنمونهگیری (Oversampling): در این روش، تعداد نمونههای کلاس اقلیت با استفاده از تکنیکهایی مانند SMOTE افزایش مییابد.
3. اعتبارسنجی متقابل K-Fold
این تکنیک اغلب همراه با بیشنمونهگیری استفاده میشود. در اعتبارسنجی متقابل، دادهها به K بخش تقسیم شده و مدل به صورت چرخشی بر روی بخشهای مختلف آموزش میبیند. این روش از بیشبرازش (Overfitting) مدل جلوگیری میکند.

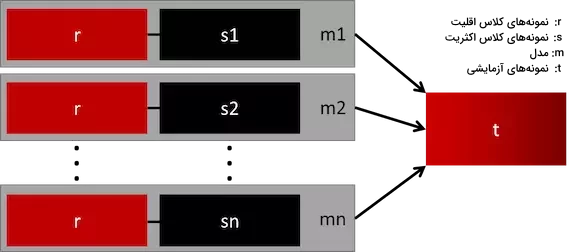
4. ترکیب مدلهای مختلف
یکی از روشهای ساده و کارآمد برای بهبود عملکرد در دادههای نامتوازن، استفاده از ترکیب مدلها است. به عنوان مثال، میتوان چندین مدل یادگیری ماشین را با دادههای مختلف از کلاس اقلیت و اکثریت آموزش داد و نتایج را ترکیب کرد.
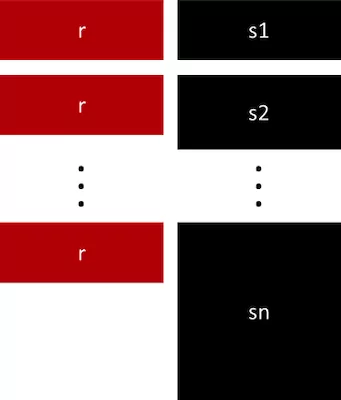
5. بازنمونهگیری با نسبتهای متفاوت
این روش شامل تغییر نسبت دادههای کلاس اقلیت و اکثریت برای هر مدل است. به عنوان مثال، یک مدل میتواند با نسبت 1:1 و مدل دیگر با نسبت 1:3 آموزش ببیند. این روش باعث میشود مدل بتواند بهتر به تعادل میان کلاسها دست یابد.
6. خوشهبندی کلاس اکثریت
در این روش، دادههای کلاس اکثریت به گروههای کوچکتر (خوشهها) تقسیم میشوند و مدل تنها با مراکز این خوشهها آموزش میبیند. این تکنیک، تنوع دادههای کلاس اکثریت را حفظ کرده و به کاهش حجم دادهها کمک میکند.
7. طراحی مدل متناسب
اگر مدلی متناسب با دادههای نامتوازن طراحی شود، نیازی به بازنمونهگیری نیست. به عنوان مثال، میتوان تابع هزینه مدل را به گونهای تنظیم کرد که خطاهای مربوط به پیشبینی کلاس اقلیت وزن بیشتری داشته باشند.
روشهای کلی مدیریت دادههای نامتوازن
به طور کلی، روشهای مدیریت دادههای نامتوازن شامل موارد زیر هستند:
- بازنمونهگیری: استفاده از بیشنمونهگیری، کمنمونهگیری یا تولید نمونههای مصنوعی.
- معیارهای ارزیابی مختلف: معیارهایی مانند F1-Score و AUC برای ارزیابی دقیقتر.
- استفاده از الگوریتمهای خاص: الگوریتمهایی مانند SMOTE و جنگل تصادفی برای مقابله با نامتوازن بودن دادهها.
جمعبندی
دادههای نامتوازن چالشهای متعددی را برای یادگیری ماشین ایجاد میکنند، اما تکنیکهای متعددی برای مدیریت آنها وجود دارد. از بازنمونهگیری گرفته تا طراحی مدلهای خاص، هر روش ویژگیها و مزایای خاص خود را دارد. با استفاده از تکنیکهای مناسب و انتخاب روشهای ارزیابی دقیق، میتوان دقت پیشبینی مدلها را بهبود داد و نتایج قابل اطمینانی ارائه کرد.