

شبکه عصبیLSTMچیست و چگونه کار میکند؟
«شبکه عصبی حافظه طولانی کوتاه مدت» (Long Short Term Memory | LSTM) یکی از مدلهای پرکاربرد در حوزه شبکههای عصبی مصنوعی است. این مدل به ویژه در حل مسائل روزمره مانند ترجمه ماشینی، تشخیص گفتار، طبقهبندی متن، تحلیل توالیهای DNA و سایر مسائلی که حفظ ترتیب زمانی دادهها اهمیت دارد، مورد استفاده قرار میگیرد. LSTM نوعی «شبکه عصبی بازگشتی» (Recurrent Neural Network | RNN) است و به دلیل ساختار داخلی خاص خود، عملکرد بهتری نسبت به مدلهای RNN ارائه میدهد.
در این مقاله ، به بررسی این موضوع میپردازیم که شبکه عصبی LSTM چیست و چگونه عمل میکند. ابتدا به دلایل پیدایش مدل LSTM و مزایای آن نسبت به شبکههای RNN خواهیم پرداخت. سپس، اجزای داخلی این شبکه را توضیح داده و به کاربردها، مزایا و معایب آن اشاره خواهیم کرد.
سایت هوش مصنوعی فارسی بیاتو ای آی
دلیل پیدایش شبکه عصبی LSTM
قبل از اینکه به این سوال پاسخ دهیم که شبکه عصبی LSTM چیست، لازم است به دلایل پیدایش آن بپردازیم و بررسی کنیم که این نوع شبکه عصبی چه مزایای خاصی نسبت به مدلهای قبلی دارد. شبکههای عصبی معمولی مانند پرسپترون در پردازش ورودی و خروجی با ابعاد متغیر با چالشهایی مواجه بودند و نمیتوانستند در حل مسائلی مانند موارد زیر به کار گرفته شوند:
-
- توصیف تصویر: در این مسئله، ورودی شبکه عصبی تصاویر هستند و مدل باید متنی تولید کند که تصویر را توصیف کند.
-
- تحلیل احساسات متن: در این نوع مسئله، ورودی شبکه عصبی متن است و مدل باید نوع احساس (مثبت، منفی، خنثی) را شناسایی کند.
-
- ترجمه ماشینی: در اینجا، ورودی شبکه عصبی متنی به زبان مبدا است و مدل باید آن را به زبان دیگری ترجمه کند.
به دلیل محدودیتهای موجود در شبکههای عصبی معمولی برای حل چنین مسائلی، ایده شبکههای عصبی بازگشتی (RNN) در سال ۱۹۸۶ مطرح شد و به دنبال آن، معماری معروف LSTM در سال ۱۹۹۷ ارائه گردید. به عبارت دیگر، ماهیت بازگشتی شبکههای عصبی RNN و LSTM این امکان را فراهم میآورد که برای آموزش مدلها از دادههای آموزشی با ابعاد متغیر استفاده شود.
این ویژگیها باعث شدهاند که LSTM به یکی از ابزارهای کلیدی در یادگیری عمیق و پردازش زبان طبیعی تبدیل شود.

معرفی شبکه عصبی LSTM و تفاوت آن با RNN
در مقاله قبلی مجله فرادرس با عنوان “شبکه عصبی بازگشتی چیست”، به طور جامع ساختار داخلی شبکه RNN توضیح داده شده است. از آنجایی که شبکه عصبی LSTM نوعی از شبکه RNN به شمار میآید، علاقهمندان میتوانند با مطالعه آن مقاله، با نحوه عملکرد و ویژگیهای شبکه RNN آشنا شوند. یکی از مهمترین معایب مدل RNN این بود که به دلیل اشتراک پارامترها در تمامی سلولهای RNN، اطلاعات حاصل از دادههای اولیه به تدریج از بین میرفت، به ویژه زمانی که طول دادههای ورودی بسیار زیاد بود.
به عبارت دیگر، شبکه عصبی RNN قادر به حفظ جزئیات دادههای گذشته نبود. به همین دلیل، تغییراتی در ساختار داخلی آن ایجاد شد و شبکه عصبی جدیدی با نام “شبکه عصبی حافظه طولانی کوتاه مدت” یا LSTM معرفی گردید. در ادامه این مقاله، به معرفی LSTM خواهیم پرداخت و عملکرد هر یک از اجزای آن را به تفصیل شرح خواهیم داد.
این تغییرات در ساختار LSTM به آن امکان میدهد که اطلاعات را به طور مؤثرتری ذخیره و پردازش کند، که این امر آن را به ابزاری قدرتمند در زمینه یادگیری عمیق و پردازش زبان طبیعی تبدیل کرده است.
شبکه عصبی LSTM چیست؟
بیش از ۲۰ سال از معرفی شبکه عصبی LSTM میگذرد و این شبکه همچنان به عنوان یکی از محبوبترین معماریهای شبکه عصبی بازگشتی شناخته میشود. اما چه عواملی باعث محبوبیت LSTM شده است؟ همانطور که در بخش قبلی اشاره شد، مدل RNN قادر به حفظ اطلاعات گذشته به طور مؤثر نیست و این موضوع به ویژه در شبکههای بزرگ میتواند مشکلساز باشد. به طور دقیقتر، مدل RNN تنها دادههای اخیر را در حافظه کوتاهمدت خود ذخیره میکند و به محض پر شدن این حافظه، قدیمیترین اطلاعات به سادگی حذف و با دادههای جدید جایگزین میشوند.
در ساختار مدل LSTM، حافظه بلندمدتی وجود دارد که اطلاعات مهم و مورد نیاز در آن نگهداری میشود. این حافظه بلندمدت به عنوان «حالت سلول» (Cell State) شناخته میشود. علاوه بر این، LSTM دارای یک حافظه کوتاهمدت است که به آن «حالت پنهان» (Hidden State) گفته میشود و اطلاعات کوتاهمدت از مراحل محاسبات قبلی را ذخیره میکند. به این ترتیب، شبکه عصبی LSTM از دو نوع حافظه تشکیل شده است و به همین دلیل به آن «شبکه عصبی حافظه طولانی کوتاهمدت» میگویند.
در تصویر زیر، نمای کلی از معماری شبکه LSTM را مشاهده میکنید:
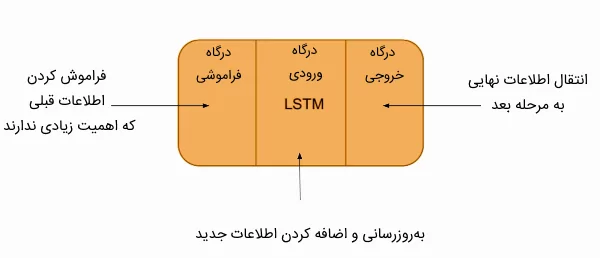
ساختار درونی شبکه عصبی LSTM
همانطور که در تصویر مشاهده میشود، شبکه عصبی LSTM از سه درگاه اصلی تشکیل شده است که هر یک پردازشی را بر روی داده ورودی انجام میدهند و در نهایت خروجی به مرحله زمانی بعدی ارسال میشود. این سه درگاه عبارتند از:
-
- درگاه ورودی (Input Gate)
-
- درگاه خروجی (Output Gate)
-
- درگاه فراموشی (Forget Gate)
قبل از اینکه به توضیحات دقیقتری درباره اجزای درونی هر یک از این درگاهها بپردازیم، در قسمت بعدی این مقاله به معرفی فیلمهای آموزشی مرتبط با یادگیری عمیق خواهیم پرداخت تا علاقهمندان به این حوزه بتوانند برای یادگیری مفاهیم تخصصی هوش مصنوعی از آنها بهرهمند شوند.
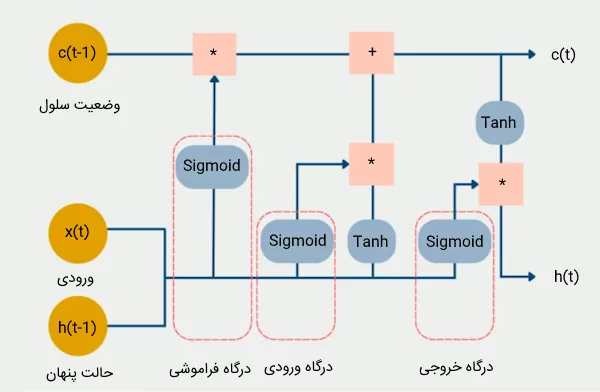
معماری شبکه عصبی LSTM
همانطور که اشاره کردیم، شبکه عصبی LSTM از سه درگاه اصلی به نامهای درگاه فراموشی، درگاه ورودی و درگاه خروجی تشکیل شده است. هر یک از این درگاهها پردازشی را بر روی دادهها با اهداف مختلف انجام میدهند. در ادامه، به توضیح دقیقتر این درگاهها میپردازیم.
درگاه فراموشی در شبکه عصبی LSTM چیست؟
در درگاه فراموشی مدل LSTM، تصمیمگیری میشود که کدام اطلاعات جاری و گذشته حفظ شوند و کدامیک باید حذف گردند. ورودی این درگاه شامل وضعیت پنهان از مرحله قبلی و ورودی فعلی است. این مقادیر به یک «تابع فعالسازی سیگموئید» (Sigmoid Function) وارد میشوند که تنها میتواند مقادیری بین ۰ و ۱ را در خروجی ارائه دهد. مقدار ۰ به این معنی است که اطلاعات قبلی میتوانند فراموش شوند، زیرا احتمالاً اطلاعات جدید و مهمتری وجود دارد. عدد ۱ نیز به این معنی است که اطلاعات قبلی باید حفظ شوند.
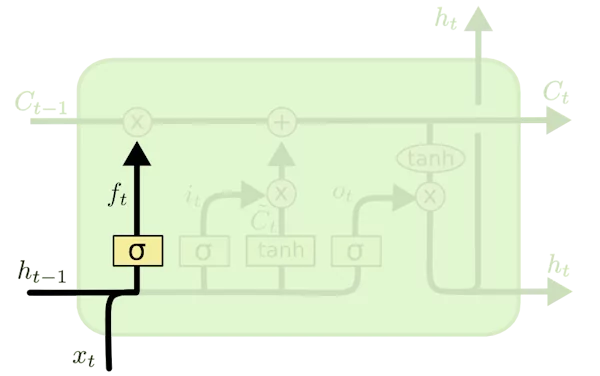
نتیجه تابع سیگموئید با مقدار وضعیت سلول (Cell State) ضرب میشود تا مشخص شود که آیا اطلاعات قبلی باید حذف شوند یا در مدل باقی بمانند. معادله درگاه فراموشی به صورت زیر است:
f_t=σ(x_t∗U_f+(h_{t-1})∗W-f)ft=σ(x_t∗U_f+(h_{t-1})∗W_f)
معادله بالا از مقادیر زیر تشکیل شده است:
- (x_t): این متغیر ورودی مربوط به زمان فعلی را مشخص میکند.
- (U_f): این متغیر وزنهای مربوط به مدل LSTM است که با مقدار ورودی ضرب میشود.
- (h_{t-1}): این متغیر حالت پنهان (hidden state) مربوط به زمان قبلی را مشخص میکند.
- (W_f): این متغیر وزنهای مربوط به مدل LSTM است که با مقادیر متغیر حالت پنهان ضرب میشوند.
پس از ضرب مقادیر ورودی LSTM با وزنهای درگاه فراموشی، مقدار حاصل شده به تابع سیگموئید داده میشود تا عددی بین ۰ و ۱ حاصل شود. در نهایت، خروجی این درگاه با مقدار وضعیت سلول زمان قبلی یا همان (C_{t-1}) ضرب میشود تا تصمیمگیری شود که آیا اطلاعات قبلی در مدل باقی بمانند و به مرحله بعد منتقل شوند یا خیر. به عبارتی، میتوان معادلههای زیر را برای این تصمیمگیری در نظر گرفت:
Ct−1∗ft=0…ifft=0Ct−1∗ft=0…ifft=0
Ct−1∗ft=Ct…ifft=1
این معادلات نشاندهنده نحوه مدیریت اطلاعات در درگاه فراموشی LSTM هستند و به حفظ یا حذف اطلاعات کمک میکنند.
درگاه ورودی در شبکه LSTM چیست؟
برای درک بهتر وظیفه درگاه ورودی در شبکه عصبی LSTM، میتوانیم از یک مثال ساده استفاده کنیم. فرض کنید دو جمله درباره فردی به نام علی داریم:
جمله اول: علی شنا کردن بلد است.
جمله دوم: او از طریق تلفن به من گفت که به مدت چهار سال در نیروی دریایی خدمت کرده است.
این دو جمله اطلاعات متفاوتی درباره علی ارائه میدهند. حالا با توجه به جمله اول، کدام اطلاعات جمله دوم برای ما مهمتر است؟ آیا اینکه او با تلفن صحبت کرده یا اینکه در نیروی دریایی خدمت کرده است؟ در واقع، مهمترین نکته این است که علی در نیروی دریایی بوده است و این اطلاعات است که مدل LSTM باید برای محاسبات بعدی خود به خاطر بسپارد. در اینجا، وظیفه حفظ اطلاعات مهم بر عهده درگاه ورودی است.
فرمول درگاه ورودی به صورت زیر است:
i_t=σ(x_t∗U_i+h_t−1∗W_i+b_i)
-
- ( x_t ): این متغیر ورودی مربوط به زمان فعلی را مشخص میکند.
-
- ماتریس وزنی ورودی ( U_i ): اهمیت یا تأثیرگذاری ورودی را بر خروجی مدل تعیین میکند.
-
- ( h_{t-1} ): اطلاعاتی است که مدل از ورودیهای قبلی دریافت کرده و در حافظه خود نگه داشته است.
-
- ماتریس وزنی ورودی ( W_i ): نشاندهنده این است که چگونه ورودی جدید با اطلاعات گذشته در مدل ترکیب میشود.
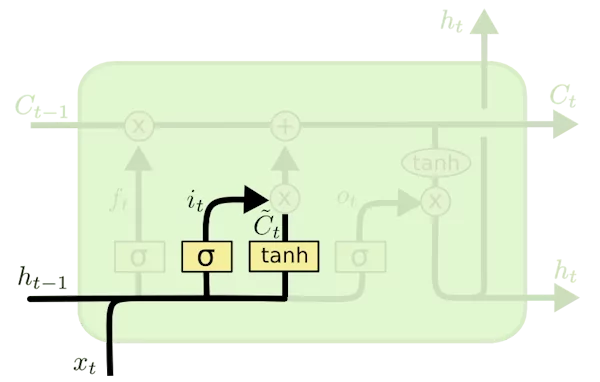
همانطور که در فرمول بالا مشاهده میشود، برای درگاه ورودی از تابع سیگموئید استفاده شده است تا اطلاعات غیرمهم ورودی حذف شوند. به عبارت دیگر، اگر خروجی این تابع نزدیک به عدد ۱ باشد، به شبکه میگوید که بخش زیادی از داده ورودی باید به اطلاعات وضعیت سلول فعلی (( C_t )) اضافه شود تا به مرحله بعدی شبکه منتقل گردد. همچنین، این درگاه شامل تابع فعالسازی دیگری به نام tanh است که مشخص میکند اطلاعات وضعیت سلول قبلی تا چه حد تحت تأثیر داده ورودی جدید قرار میگیرد.
به عبارتی، این تابع تعیین میکند که اطلاعات قبلی تا چه حد باید توسط داده ورودی شبکه بهروزرسانی شوند. این تابع مقادیر را به بازه عددی ۱ و -۱ نگاشت میکند. خروجی تابع tanh هر چه به عدد ۱ نزدیکتر باشد، به این معناست که اطلاعات ورودی شبکه بسیار مهم هستند و باید اطلاعات قبلی بهطور قابل توجهی تحت تأثیر داده ورودی قرار گیرند و بهروزرسانی شوند. اگر خروجی این تابع به عدد -۱ نزدیک باشد، بهروزرسانی اطلاعات قبلی به صورت ناچیز انجام میشود. فرمول این بخش از درگاه ورودی به صورت زیر است:
C~=tanh(x_t∗U_c+h_t−1∗W_c+b_c)
در نهایت، مقدار سلول وضعیت فعلی با استفاده از فرمول زیر محاسبه خواهد شد:
C_t=f_t∗C_t−1+i_t∗C~
این فرمولها به ما کمک میکنند تا درک بهتری از عملکرد درگاه ورودی در شبکههای LSTM داشته باشیم.
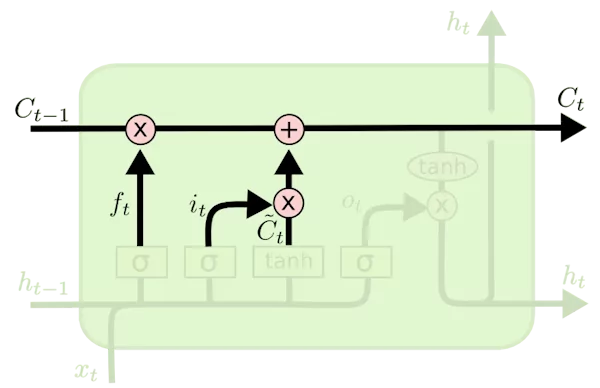
درگاه خروجی در LSTM
درگاه خروجی در شبکههای عصبی بازگشتی LSTM، خروجی نهایی را بر اساس وضعیت فعلی سلول حافظه مشخص میکند. این درگاه مانند سایر درگاههای LSTM دارای یک ماتریس وزنی است که مقادیر آن طی روش «پس انتشار» (Backpropagation) بهروز میشوند. اگر با این روش آشنایی ندارید، میتوانید با مطالعه مطلب قبلی از مجله فرادرس با عنوان «روش پس انتشار — از صفر تا صد» با نحوه بهروزرسانی وزنهای شبکه عصبی آشنا شوید.
ماتریس وزن، ورودی جاری (( x_t )) و خروجی حالت پنهان قبلی (( h_{t-1} )) را دریافت کرده و عمل ضرب را روی آنها انجام میدهد. نتیجه حاصل شده به تابع فعالسازی سیگموئید ارسال میشود. در انتها، مقدار خروجی تابع سیگموئید با مقدار وضعیت سلول که از تابع تانژانت (tanh) عبور کرده است، ضرب میشود تا مقدار نهایی ( h_t ) حاصل شود.
به منظور درک بهتر عملکرد درگاه خروجی شبکه LSTM، میتوانیم از یک مثال ملموس استفاده کنیم. فرض کنید جمله زیر را داریم:
«علی به تنهایی با دشمن جنگید و برای کشورش جان باخت. به خاطر فداکاریهایش، __ شجاع.»
هدف این است که جمله دوم را کامل کنیم. زمانی که کلمه «شجاع» را میبینیم، میفهمیم که در مورد یک فرد صحبت میکنیم. در این جمله، فقط علی شجاع است و نمیتوانیم بگوییم دشمن یا کشور شجاع هستند. پس بر اساس انتظار فعلی، باید یک کلمه مرتبط برای پر کردن جای خالی پیدا کنیم. یافتن کلمه همان کاری است که درگاه خروجی انجام میدهد.
به عبارتی میتوان گفت درگاه خروجی در شبکههای عصبی بازگشتی LSTM، جریان اطلاعات را کنترل میکند و تصمیم میگیرد کدام قسمت از خروجی سلول در زمان فعلی به خروجی نهایی مدل مرتبط است. در مثال بالا، کلمه «علی» از جمله اول، مرتبطترین اطلاعات با کلمه «شجاع» در جمله دوم است. بنابراین، گیت خروجی مدل یادگیری ماشین روی کلمه «علی» تمرکز میکند و آن را به عنوان خروجی نهایی برای پر کردن جای خالی جمله دوم در نظر میگیرد.
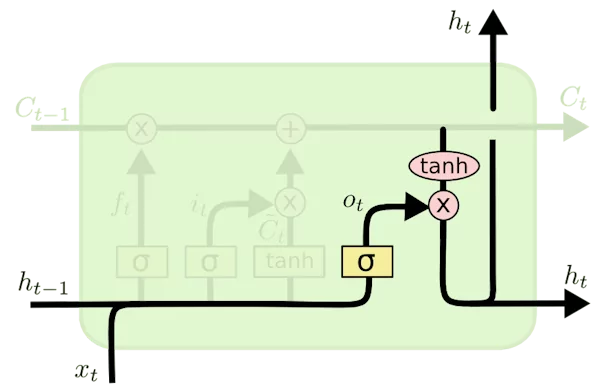
فرمول زیر، نحوه محاسبه درگاه خروجی را نشان میدهد:
o_t=σ(x_t∗U_o+h_t−1∗W_o+b_o
و مقدار خروجی حالت پنهان به صورت زیر محاسبه میشود:
h_t=o_t∗tanh(C_t)h_t=o_t∗tanh(C_t)
این فرمولها به ما کمک میکنند تا درک بهتری از عملکرد درگاه خروجی در شبکههای LSTM داشته باشیم.
شبکه بازگشتی دوطرفه LSTM چیست؟
شبکههای بازگشتی بلندمدت دوطرفه (Bidirectional LSTMs) نوعی از معماری شبکه عصبی بازگشتی (RNN) هستند که اطلاعات ورودی را در دو سمت مختلف یعنی به طرف جلو و به طرف عقب پردازش میکنند. در یک شبکه عصبی LSTM معمولی، سیگنالها صرفاً از گذشته به آینده حرکت میکنند و بر اساس دادههای پیشین، پیشبینیهایی صورت میگیرد. بهعکس، در شبکههای بازگشتی دوطرفه، مدل علاوه بر اطلاعات گذشته، به اطلاعات آینده نیز توجه میکند و ارتباطات بین دادهها را در هر دو سمت ثبت میکند.
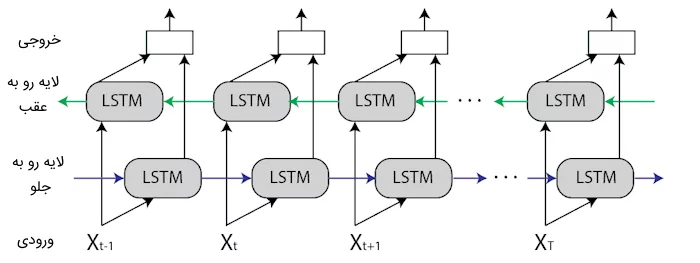
تصویر فوق، ساختار یک شبکه عصبی BiLSTM را نمایش میدهد. همانطور که مشاهده میشود، در لایه اول، دادهها از ابتدا به انتها پردازش میشوند و مدل LSTM در حین پردازش داده جاری یا(X_t)، دادههای قبلی را مدنظر قرار میدهد. در لایه دوم، مدل LSTM دادهها را از انتها به ابتدا دریافت میکند و در نهایت برای محاسبه خروجی، اطلاعات هر دو لایه به کار گرفته میشوند. شبکههای بازگشتی دوطرفه بهویژه برای مواردی که نیاز به درک عمیقتری از توالی ورودی دارند، کاربرد دارند. کاربردهایی مانند «پردازش زبان طبیعی» (Natural Language Processing | NLP) از قبیل تحلیل احساسات، ترجمه ماشینی و «تشخیص موجودیت نامدار» (Named Entity Recognition | NER) میتوانند بهوسیله این نوع مدل یادگیری عمیق پیادهسازی شوند.
کاربردهای شبکه عصبی LSTM چیست؟
پس از بررسی اینکه شبکه عصبی LSTM چیست و چه ساختاری دارد، به بررسی کاربردهای آن میپردازیم. شبکه عصبی حافظه طولانی کوتاه مدت (LSTM) نوعی از شبکههای عصبی بازگشتی است که به دلیل کارایی بالا در موارد مختلف بهکار گرفته میشود. در ادامه به برخی از کاربردهای این مدل پرداخته میشود:
- شبیهسازی زبان: شبکههای عصبی LSTM در حوزه پردازش زبان طبیعی مانند ترجمه ماشینی، مدلسازی زبان و خلاصهسازی متن استفاده میشوند. این شبکهها با تشخیص روابط بین کلمات داخل جملات میتوانند جملات معنادار با ساختار گرامری صحیح تولید کنند.
- تشخیص گفتار: LSTM در وظایف تشخیص گفتار، نظیر تبدیل گفتار به متن و رونویسی متن به متن دیگر، به کار میرود. این مدل یادگیری عمیق قادر به شناسایی الگوهای گفتاری و تطبیق آنها با متن مناسب است.
- تحلیل احساسات: شبکههای عصبی LSTM میتوانند برای تشخیص احساسات موجود در متن استفاده شوند. این مدل با یادگیری روابط بین کلمات و احساسات مرتبط، قادر به دستهبندی متون به طبقات مثبت، منفی یا خنثی است.
- پیشبینی سریهای زمانی: LSTM با تحلیل روابط بین مقادیر گذشته و آینده، میتواند برای پیشبینی مقادیر آینده در یک سری زمانی به کار گرفته شود.
- تحلیل ویدئو: شبکه عصبی LSTM میتواند با یادگیری روابط بین فریمهای ویدیویی و عناصر مرتبط با آنها، برای تجزیه و تحلیل ویدئو مورد استفاده قرار گیرد.
- تشخیص دستخط: مدلهای LSTM میتوانند با بررسی رابطه بین تصاویر دست خط و متن مربوطه، در تشخیص دستخط افراد به کار گرفته شوند.
این کاربردها نشاندهنده قدرت و انعطافپذیری شبکههای عصبی LSTM در حوزههای مختلف تکنولوژی و هوش مصنوعی هستند.
مزایا و معایب شبکه عصبی LSTM چیست؟
در این مقاله به بررسی شبکه عصبی LSTM و کاربردهای آن پرداختیم. این مدل عمیق از جمله پرکاربردترین شبکههای عصبی به شمار میآید و به دلیل مزایای متعددش در حل مسائل مختلف استفاده میشود. در ادامه، مهمترین مزایای LSTM را معرفی میکنیم:
- مدیریت وابستگیها: LSTM در شناسایی روابط میان دادهها با فواصل طولانی عملکرد بسیار خوبی دارد. این ویژگی باعث میشود که این مدل برای کارهایی مانند ترجمه ماشینی، تشخیص گفتار و تحلیل سریهای زمانی بسیار مناسب باشد.
- رفع مشکل محو شدن گرادیان: شبکههای عصبی بازگشتی سنتی (RNN) با مشکل محو شدن گرادیان مواجهاند که ممکن است یادگیری آنها را محدود کند. معماری خاص LSTM باعث میشود که این مشکل کاهش یابد و این مدل از دنبالههای طولانیتر به شکل مؤثرتری یاد بگیرد.
- مدلسازی دادههای ترتیبی پیچیده: LSTM قادر است الگوها و روابط پیچیده را در دادههای ترتیبی بهخوبی شناسایی کند. این قابلیت به LSTM اجازه میدهد تا در وظایفی مانند تحلیل احساسات متن، شرح ویدیو و تشخیص ناهنجاری عملکرد خوبی داشته باشد.
با وجود مزایای چشمگیر، شبکه عصبی LSTM دارای معایبی نیز است که در ادامه به آنها اشاره میکنیم:
- پیچیدگی محاسباتی: آموزش LSTM نسبت به مدلهای سادهتر سختتر است. این شبکه عصبی به محاسبات سنگینتری نیاز دارد و برای آموزش مؤثر، به دادههای بیشتری نیازمند است.
- وابستگی به دادهها: LSTM بهترین عملکرد خود را زمانی که بر روی مجموعه دادههای بزرگ آموزش دیده باشد، نشان میدهد. در صورتی که دادههای محدودی برای آموزش استفاده شود، ممکن است مدل نتواند بهخوبی یاد بگیرد و عملکرد ضعیفی از خود به نمایش بگذارد.
- قابلیت تفسیرپذیری: فهمیدن اینکه مدل LSTM چه اطلاعاتی از دادهها استنباط کرده است، میتواند چالشبرانگیز باشد. این موضوع ممکن است فرآیند اشکالزدایی و توضیح عملکرد مدل را دشوار کند.

جمعبندی
شبکههای عصبی بازگشتی از جمله مدلهای پرکاربرد یادگیری عمیق هستند که به خاطر ویژگی بازگشتیشان، در زمینههایی نظیر پردازش زبان طبیعی و تحلیل سریهای زمانی استفاده میشوند. شبکه عصبی RNN به عنوان مدل اولیه این شبکهها با مشکل محو شدن گرادیان در بسیاری از مسائل هوش مصنوعی عملکرد قابل قبولی نداشت. در مقابل، شبکه عصبی LSTM با معماری پیچیدهتر خود، میتواند به بهبود عملکرد و کاهش مشکلات اولیه RNN کمک کند. از آنجا که مدل LSTM در حل مسائل مختلف هوش مصنوعی بسیار موثر است، در این مقاله به توضیح این شبکه پرداختیم و به این سوال پاسخ دادیم که LSTM چیست و چگونه دادهها را پردازش میکند.
