

برنامهنویسی درخت تصمیم در یادگیری ماشین
در دنیای یادگیری ماشین، برنامهنویسی درخت تصمیم یکی از روشهای مؤثر برای دستهبندی دادهها به شمار میرود. برای پیادهسازی این الگوریتم، میتوان از کتابخانهها و ابزارهای پایتون بهره برد. یکی از کلاسهای کلیدی در این زمینه، DecisionTreeClassifier است که قابلیت انجام «دستهبندیهای چند کلاسه» (Multi-Class Classification) را با استفاده از درخت تصمیم در مجموعه دادهها دارد. این کلاس مانند سایر دستهبندیکنندههای پایتون، دو آرایه به عنوان ورودی دریافت میکند که در ادامه به آنها پرداخته خواهد شد.
درخت تصمیم (Decision Tree) به عنوان یکی از الگوریتمهای محبوب در حوزه یادگیری ماشین شناخته میشود و میتوان از آن برای حل مسائل «طبقهبندی» (Classification) و «رگرسیون» (Regression) استفاده کرد. این الگوریتم به دلیل سادگی در تفسیر و پیادهسازی، گزینهای مناسب برای افراد مبتدی در یادگیری ماشین است.
در این مقاله، به بررسی مفهوم درخت تصمیم و اصطلاحات تخصصی مرتبط با آن خواهیم پرداخت. همچنین، انواع معیارهای انتخاب ویژگی در این الگوریتم را به همراه مثالهای کاربردی توضیح خواهیم داد. در ادامه، به مزایا و معایب این الگوریتم و کاربردهای آن اشاره میکنیم و با استفاده از یک مثال برنامهنویسی، نحوه پیادهسازی درخت تصمیم را آموزش خواهیم داد.
با ما همراه باشید تا به دنیای جذاب درخت تصمیم و کاربردهای آن در یادگیری ماشین بپردازیم!
اگر به آموزش هوش مصنوعی علاقه داری سایت آموزش هوش مصنوعی رو از دست نده.
درخت تصمیم چیست؟
الگوریتم درخت تصمیم یکی از انواع الگوریتمهای یادگیری ماشین با رویکرد یادگیری نظارت شده است که برای حل مسائل رگرسیون و طبقهبندی مورد استفاده قرار میگیرد. این الگوریتم دارای یک ساختار درختی معکوس است که شباهت زیادی به فلوچارت دارد و به راحتی میتواند تفکر انسان را در سطوح مختلف تقلید کند. به همین دلیل، درک و تفسیر عملکرد درخت تصمیم بسیار آسان است. به عبارتی، درخت تصمیم به عنوان «جعبه سفید» (White Box) شناخته میشود، زیرا برخلاف الگوریتمهای «جعبه سیاه» (Black Box) مانند شبکههای عصبی، منطق تصمیمگیری داخلی آن قابل درک و تفسیر است.
ساختار سلسلهمراتبی درخت تصمیم، بستری را فراهم میکند که این الگوریتم در هر سطح از درخت، بر اساس یک سری قوانین از پیش تعریف شده، به تقسیم دادهها در شاخههای مختلف میپردازد. پیش از توضیح دقیقتر عملکرد این الگوریتم، لازم است برخی اصطلاحات تخصصی مرتبط با درخت تصمیم را معرفی کنیم تا خوانندگان بتوانند بهتر با روال کار این الگوریتم آشنا شوند.
اصطلاحات مربوط به درخت تصمیم
در ادامه، به بررسی برخی اصطلاحات کلیدی درخت تصمیم میپردازیم تا مخاطبان بتوانند مفاهیم بخشهای بعدی را به راحتی درک کنند:
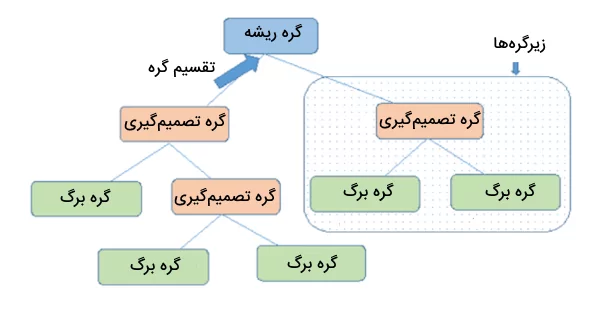
- گره (Node) و یال (Edge): درخت تصمیم از چندین گره و شاخه تشکیل شده است. شاخهها، گرههای درخت را به یکدیگر متصل میکنند و گرهها بر اساس شرایط و قوانین تعریف شده، دادهها را تقسیم میکنند.
- گره ریشه (Root Node): اولین گره در درخت است که تقسیمبندی دادهها از این گره آغاز میشود.
- گره تصمیمگیری (Decision Node): گرهای است که به دو یا چند گره دیگر تقسیم میشود و نشاندهنده یک تصمیم یا شرط میانی است.
- گره برگ (Leaf Node): به گرههای آخرین سطح درخت، گره برگ گفته میشود که دیگر قابل تقسیم به گرههای دیگر نیستند و نتیجه یا پیشبینی نهایی درخت را نشان میدهند. این گرهها همچنین به عنوان «گرههای انتهایی» (Terminal Node) شناخته میشوند.
- شاخه (Branch) یا زیر درخت (Sub-Tree): زیرمجموعهای از کل درخت تصمیمگیری است که مسیری از درخت را نشان میدهد.
- هرس (Pruning): این فرایند شامل حذف گرههای غیرضروری از درخت برای جلوگیری از «بیش برازش» (Overfitting) و سادهسازی مدل است.
- گره والد (Parent Node) و گره فرزند (Child Node): در یک درخت تصمیمگیری، گرهای که به زیرمجموعهای از گرهها تقسیم میشود، گره والد نامیده میشود و گرههایی که از گره والد نشأت میگیرند، گرههای فرزند نام دارند. گره والد نشاندهنده یک تصمیم یا شرط است، در حالی که گرههای فرزند نشاندهنده نتایج بالقوه یا تصمیمات بیشتر بر اساس آن شرط هستند.
حال که با اجزای اصلی الگوریتم درخت تصمیم آشنا شدید، در ادامه به نحوه طراحی و ترسیم این الگوریتم به همراه ارائه مثالهای ساده و کاربردی خواهیم پرداخت تا درک بهتری از آن پیدا کنید.
رسم درخت تصمیم
درختهای تصمیمگیری برخلاف درختهای طبیعی از بالا به پایین رشد میکنند. به این معنا که گره ریشه در بالای درخت قرار دارد و سپس در سطوح پایینتر به گرههای متعددی تقسیم میشود. به طور ساده، درختهای تصمیمگیری مجموعهای از سوالات «اگر-آنگاه» (if-else) هستند. هر گره یک سوال را مطرح میکند و بر اساس پاسخ به آن سوال، مسیر حرکت به گرههای بعدی مشخص میشود. این سوالات به ویژگیهای دادههای مسئله مربوط میشوند. برای درک بهتر این موضوع، از یک مثال ساده استفاده میکنیم.
فرض کنید مجموعه دادهای داریم که هدف آن پیشبینی وضعیت هوا (ابری یا بارانی) و امکان بازی در فضای بیرون است. این مجموعه داده شامل اطلاعاتی از وضعیت هوا برای چندین روز متوالی است که شامل وضعیت هوا (آفتابی، ابری، بارانی)، دما، میزان رطوبت و وضعیت باد میباشد.
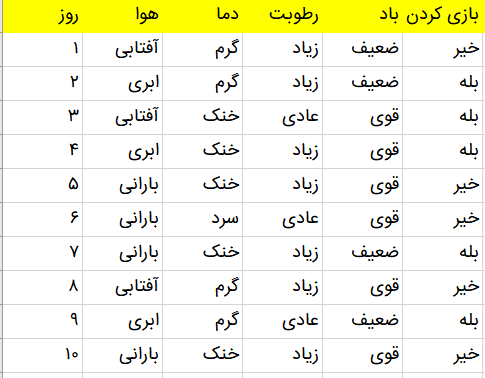
برای این مثال، میتوانیم یک درخت تصمیم بسازیم که در هر سطح از درخت، دادهها را بر اساس ویژگیهای تعریف شده تقسیمبندی کند تا در نهایت پاسخ مسئله مشخص شود. درخت تصمیم زیر، نمایی از شیوه دستهبندی دادهها را نشان میدهد. در ابتدا، وضعیت هوا بررسی میشود. اگر هوا ابری باشد، به پاسخ نهایی میرسیم که نشان میدهد در هوای ابری میتوان در فضای بیرون بازی کرد. اگر پاسخ سوال در گره ریشه آفتابی باشد، درخت تصمیم به بررسی ویژگی بعدی یعنی «میزان رطوبت و وضعیت باد» میپردازد. در این مرحله، سوال دیگری مطرح میشود: آیا میزان باد شدید است یا ضعیف؟ اگر وضعیت باد ضعیف و هوا بارانی باشد، فرد میتواند بیرون از خانه بازی کند. به این ترتیب، درخت تصمیمگیری با پرسیدن سوالات متوالی پیرامون ویژگیهای دادهها، فرد را به سمت یک تصمیم نهایی هدایت میکند.
همانطور که در تصویر مربوط به دادههای الگوریتم درخت تصمیم مشاهده میکنید، ویژگی ابری بودن هوا به سایر ویژگیها تقسیم نشده است. علت توقف تقسیم در این نقطه چیست؟ برای پاسخ به این سوال، نیاز به درک مفاهیم دیگری مانند «آنتروپی» (Entropy)، «کسب اطلاعات» (Information Gain) و «شاخص جینی» (Gini Index) داریم که در بخشهای بعدی به آنها خواهیم پرداخت. اما به طور کلی، میتوان گفت که با توجه به دادههای آموزشی، هرگاه هوا ابری باشد، همیشه میتوان بیرون از خانه بازی کرد. از آنجایی که در این گره، بینظمی یا تردیدی در خروجی وجود ندارد، نیازی به تقسیم بیشتر آن نیست.
با این توضیحات، میتوانیم به درک بهتری از نحوه رسم و عملکرد درخت تصمیم برسیم و به بررسی جزئیات بیشتر در بخشهای بعدی بپردازیم.
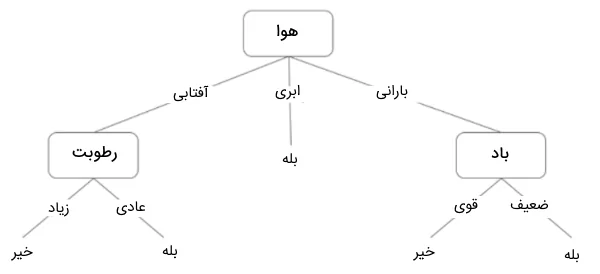
همانطور که در تصویر مربوط به دادههای الگوریتم درخت تصمیم مشاهده میکنید، ویژگی ابری بودن هوا به سایر ویژگیها تقسیم نشده است. علت توقف تقسیم در این نقطه چیست؟ برای پاسخ به این سوال، نیاز به درک مفاهیم دیگری مانند «آنتروپی» (Entropy)، «کسب اطلاعات» (Information Gain) و «شاخص جینی» (Gini Index) داریم که در بخشهای بعدی به آنها خواهیم پرداخت. اما به طور کلی، میتوان گفت که با توجه به دادههای آموزشی، هرگاه هوا ابری باشد، همیشه میتوان بیرون از خانه بازی کرد. از آنجایی که در این گره، بینظمی یا تردیدی در خروجی وجود ندارد، نیازی به تقسیم بیشتر آن نیست.
با این توضیحات، میتوانیم به درک بهتری از نحوه رسم و عملکرد درخت تصمیم برسیم و به بررسی جزئیات بیشتر در بخشهای بعدی بپردازیم.

درخت تصمیم چگونه کار میکند؟
برای ارائه پاسخ جامعتری به این پرسش که درخت تصمیم چیست، لازم است به نحوه عملکرد آن نیز اشاره کنیم. عملیات درخت تصمیم از چندین مرحله تشکیل شده است که میتوان آنها را به صورت زیر خلاصه کرد:
ساخت گره ریشه: کار الگوریتم درخت تصمیم با ساخت گره ریشه آغاز میشود و کل مجموعه دادهها در این گره قرار میگیرند.
انتخاب بهترین ویژگی: با استفاده از معیارهای انتخاب ویژگی مانند Gini و بهرهوری اطلاعاتی، بهترین ویژگی که بیشترین تمایز را میان دادهها ایجاد میکند، برای تقسیم دادهها در گره ریشه انتخاب میشود.
تقسیم دادهها: ویژگی انتخابشده به عنوان یک گره تصمیمگیری در نظر گرفته میشود و بر اساس آن، مجموعه داده به زیرمجموعههای کوچکتر تقسیم میشود.
تکرار مراحل ۲ و ۳: مراحل انتخاب بهترین ویژگی و تقسیم دادهها به صورت «بازگشتی» (Recursive) برای هر زیرمجموعه (گره فرزند) تکرار میشود تا زمانی که یکی از شرایط زیر برقرار شود:
تمام نمونههای موجود در گره فرزند متعلق به یک کلاس یکسان باشند.
هیچ ویژگی دیگری برای گسترش درخت تصمیم وجود نداشته باشد.
هیچ نمونه دیگری برای ساخت گره فرزند جدید باقی نمانده باشد.
برای درک دقیقتر این سوال که درخت تصمیم چیست و بر چه اساسی کار میکند، در بخش بعدی به معیارهای انتخاب ویژگی در این الگوریتم خواهیم پرداخت.

معیار انتخاب ویژگی در درخت تصمیم
پس از بررسی اینکه درخت تصمیم چیست و توضیح اصطلاحات فنی آن، اکنون به معیارهای انتخاب ویژگی برای هر سطح درخت میپردازیم. به عبارت دیگر، معیار انتخاب ویژگی روشی است که در الگوریتمهای درخت تصمیم برای ارزیابی مفید بودن ویژگیهای مختلف در طبقهبندی مجموعه دادهها استفاده میشود. هدف اصلی این معیارها، یافتن مناسبترین ویژگی است که بتواند همگنترین دادهها را در دستههای مشابه قرار دهد و حداکثر سود اطلاعاتی را به دست آورد.
تقسیمبندی دادهها به صورت بازگشتی انجام میشود و کار الگوریتم زمانی به اتمام میرسد که همه دادههای موجود در یک گره، از ویژگیهای مشابهی برخوردار باشند یا تقسیم دادهها به بهبود نتیجه کمکی نکند. یکی از ویژگیهای مهم تقسیم داده با روش درخت تصمیم این است که این الگوریتم نیازی به استخراج دانشی خاص در مورد دادهها ندارد و میتواند با دادههایی با ابعاد بالا کار کند. سه نوع معیار انتخاب ویژگی در درخت تصمیم وجود دارد که به شرح زیر است:
-
- آنتروپی
-
- بهره اطلاعاتی
-
- شاخص جینی
در ادامه، به توضیح هر یک از این معیارها خواهیم پرداخت.

محاسبه آنتروپی در درخت تصمیم
اگر به مطالعه در مورد درخت تصمیم پرداختهاید، احتمالاً با اصطلاح «آنتروپی» آشنا هستید. آنتروپی در درخت تصمیم برای اندازهگیری میزان بینظمی در مجموعه دادهها استفاده میشود. برای درک بهتر این مفهوم، از یک مثال ساده استفاده میکنیم.
فرض کنید گروهی از دوستان میخواهند تصمیم بگیرند که یکشنبه به سینما بروند. دو فیلم «جنگ ستارگان» و «پدرخوانده» برای انتخاب وجود دارد. بر اساس آرا، ۵ نفر از دوستان تمایل دارند فیلم «جنگ ستارگان» را ببینند و ۵ نفر دیگر «پدرخوانده» را ترجیح میدهند. در اینجا سوال این است که کدام فیلم باید انتخاب شود؟
انتخاب فیلم در این شرایط دشوار است زیرا تعداد آرا برای هر دو فیلم تقریباً برابر است. این وضعیت را بینظمی مینامیم. اگر ۸ نفر به دیدن فیلم «جنگ ستارگان» و ۲ نفر به دیدن «پدرخوانده» رای میدادند، تصمیمگیری بسیار آسانتر بود. در این حالت، میتوان به راحتی گفت که اکثریت افراد به دیدن «جنگ ستارگان» تمایل دارند.
به عبارتی، مقدار آنتروپی برای نسبت نفرات ۵ به ۵ برابر با ۱ است، زیرا در این تقسیمبندی، میزان بینظمی بالا است و نمیتوان به راحتی به نتیجهگیری نهایی رسید. در حالتی که نسبت نفرات ۸ به ۲ است، مقدار آنتروپی نزدیک به ۰ میشود و در این حالت راحتتر میتوان نتیجهگیری کرد. فرمول آنتروپی به صورت زیر است:
E(S)=−p(+)logp(+)−p(−)logp(−)
- ( p(+) ): احتمال کلاس مثبت را نشان میدهد و نشاندهنده میزان احتمال تعلق یک نمونه به دسته مثبت در یک زیرمجموعه خاص از دادههای آموزشی است.
- ( p(-) ): احتمال کلاس منفی را نشان میدهد و نشاندهنده احتمال تعلق یک نمونه به دسته منفی در همان زیرمجموعه از دادههای آموزشی است.
- ( S ): زیرمجموعهای از نمونههای آموزشی است که برای محاسبه آنتروپی استفاده میشود.
آنتروپی اساساً میزان ناخالصی یک گره را اندازهگیری میکند. مقدار ناخالصی نشاندهنده درجه تصادفی بودن است و به ما میگوید که دادهها تا چه حد تصادفی هستند.
فرض کنید ۱۲ داده آموزشی با ۳ ویژگی داریم که با برچسبهای Yes و No برچسبگذاری شدهاند. ۸ داده در این مجموعه دارای برچسب Yes و ۴ داده باقیمانده با No برچسبگذاری شدهاند. اگر بخواهیم این دادهها را بر اساس ویژگی اول تقسیمبندی کنیم، گره سمت چپ شامل ۵ داده با برچسب Yes و ۲ داده با برچسب No میشود. همچنین، گره سمت راست، ۳ داده با برچسب Yes و ۲ داده با برچسب No را در بر میگیرد.
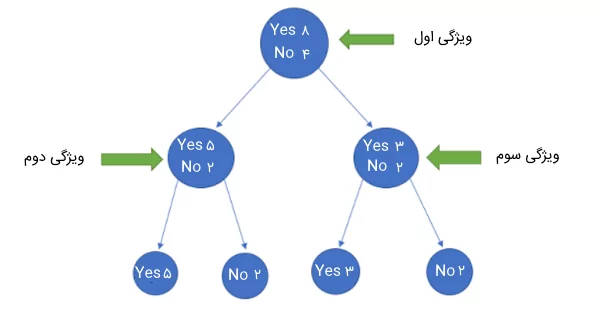
در اینجا، باید مقدار آنتروپی برای هر تقسیمبندی را محاسبه کنیم و زمانی که خلوص ۱۰۰٪ شد، آن را به عنوان یک گره برگ در نظر بگیریم. به بیان دیگر، زمانی که تمام دادههای موجود در گرهها از کلاس یکسان باشند، مقدار آنتروپی برابر با صفر است و در این حالت به بهترین نحوه طبقهبندی دادهها دست یافتهایم.
معیار بهره اطلاعاتی در درخت تصمیم چیست؟
معیار بهره اطلاعاتی (Information Gain یا IG) میزان اطلاعاتی را که از یک ویژگی به دست میآید، مشخص میکند. به عبارت دیگر، این معیار تعیین میکند که یک ویژگی چقدر مهم است. از آنجایی که ساخت درخت تصمیم به طور کلی در مورد یافتن بهترین گره برای تقسیم دادهها است، با استفاده از معیار IG میتوان اهمیت گرهها را مشخص کرد. این معیار بر پایه آنتروپی محاسبه میشود. اگر به دنبال اطلاعات بیشتری درباره این معیار و نحوه کاربرد آن در الگوریتم درخت تصمیم هستید، میتوانید از فیلم آموزشی فرادرس استفاده کنید که به طور مفصل به این موضوع اختصاص دارد.
معیار IG میزان کاهش عدم قطعیت را با توجه به یک ویژگی خاص اندازهگیری میکند و همچنین عامل تعیینکنندهای برای انتخاب ویژگی به عنوان گره تصمیم یا ریشه است. فرمول معیار IG به صورت زیر است:
InformationGain=E(Y)−E(Y∣X)InformationGain=E(Y)−E(Y∣X)
بر اساس این فرمول، معیار IG از تفاضل آنتروپی مجموعه داده و آنتروپی مجموعه داده با در نظر گرفتن یک ویژگی خاص به دست میآید. برای درک بهتر این معیار، مثالی را در نظر میگیریم. فرض کنید مسئله ما این است که مشخص کنیم آیا فرد تصمیم میگیرد به باشگاه برود یا خیر. برای این مسئله، ۳۰ داده در اختیار داریم که هر داده شامل دو ویژگی «میزان انرژی» و «مقدار انگیزه» است. از مجموع کل دادهها، ۱۶ نفر به باشگاه میروند و ۱۴ نفر قصد رفتن به باشگاه را ندارند. ویژگیهای میزان انرژی و مقدار انگیزه میتوانند مقادیر زیر را برای هر فرد شامل شوند:
-
- ویژگی مقدار انرژی: این ویژگی میتواند با مقادیر «بالا» و «پایین» مشخص شود.
-
- ویژگی مقدار انگیزه: این ویژگی میتواند سه مقدار «بدون انگیزه»، «خنثی» و «انگیزه بالا» را شامل شود.
بیایید ببینیم با استفاده از این دو ویژگی، درخت تصمیم ما چگونه ساخته میشود. ابتدا، مقدار IG را برای ویژگی انرژی محاسبه میکنیم. همانطور که قبلاً اشاره کردیم، مجموعه داده مسئله شامل ۳۰ داده است که ۱۶ داده آن شامل افرادی است که به باشگاه میروند و ۱۴ داده آن اطلاعات افرادی هستند که به باشگاه نمیروند. بر اساس ویژگی انرژی، درخت زیر را شکل میدهیم:
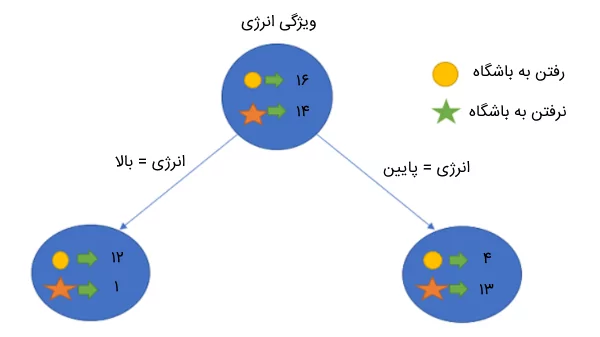
کاربرد معیار بهره اطلاعاتی در درخت تصمیم
سپس، مقدار آنتروپی کل مجموعه داده و مقدار آنتروپی دادهها بر اساس ویژگی مقدار انرژی را با استفاده از فرمول زیر محاسبه میکنیم:
[ E(Parent) = -\left(\frac{16}{30}\right) \log_2\left(\frac{16}{30}\right) – \left(\frac{14}{30}\right) \log_2\left(\frac{14}{30}\right) \approx 0.99 ]
برای محاسبه آنتروپی بر اساس ویژگی انرژی، به صورت زیر عمل میکنیم:
[ E(Parent|Energy=’high’) = -\left(\frac{12}{13}\right) \log_2\left(\frac{12}{13}\right) – \left(\frac{1}{13}\right) \log_2\left(\frac{1}{13}\right) \approx 0.39 ]
[ E(Parent|Energy=’low’) = -\left(\frac{4}{17}\right) \log_2\left(\frac{4}{17}\right) – \left(\frac{13}{17}\right) \log_2\left(\frac{13}{17}\right) \approx 0.79 ]
حال، میانگین وزندار آنتروپیهای هر یک از گرههای فرزند را به صورت زیر محاسبه میکنیم:
[ E(Parent|Energy) = \left(\frac{13}{30} \times 0.39\right) + \left(\frac{17}{30} \times 0.79\right) = 0.62 ]
در نهایت، با استفاده از فرمول زیر، مقدار IG را برای ویژگی انرژی محاسبه میکنیم:
[ \text{Information Gain} = E(Parent) – E(Parent|Energy) = 0.99 – 0.62 = 0.37 ]
در ابتدا، مقدار آنتروپی برای مجموعه داده اصلی (گره والد) حدود ۰.۹۹ بود. با توجه به مقدار به دست آمده برای معیار IG (یعنی ۰.۳۷)، میتوانیم بگوییم که اگر ویژگی انرژی را به عنوان گره ریشه انتخاب کنیم، آنتروپی مجموعه داده کاهش پیدا میکند. به همین ترتیب، میتوانیم همین کار را برای ویژگی انگیزه انجام دهیم و مقدار IG را برای آن نیز محاسبه کنیم.
[ E(Parent) = 0.99 ]
با این توضیحات، میتوانیم به درک بهتری از معیار بهره اطلاعاتی و کاربرد آن در الگوریتم درخت تصمیم برسیم.
محاسبه آنتروپی بر اساس ویژگی انگیزه
برای محاسبه آنتروپی بر اساس ویژگی انگیزه، ابتدا مقادیر آنتروپی برای هر دسته از ویژگیها را به صورت زیر محاسبه میکنیم:
- آنتروپی برای افرادی که «بدون انگیزه» هستند:
[
E(Parent|Motivation=’No Motivation’) = -\left(\frac{7}{8}\right) \log_2\left(\frac{7}{8}\right) – \left(\frac{1}{8}\right) \log_2\left(\frac{1}{8}\right) \approx 0.54
]
- آنتروپی برای افرادی که «بدون انگیزه» هستند:
- آنتروپی برای افرادی که «خنثی» هستند:
[
E(Parent|Motivation=’Neutral’) = -\left(\frac{4}{10}\right) \log_2\left(\frac{4}{10}\right) – \left(\frac{6}{10}\right) \log_2\left(\frac{6}{10}\right) \approx 0.97
]
- آنتروپی برای افرادی که «خنثی» هستند:
- آنتروپی برای افرادی که «انگیزه بالا» دارند:
[
E(Parent|Motivation=’Highly Motivated’) = -\left(\frac{5}{12}\right) \log_2\left(\frac{5}{12}\right) – \left(\frac{7}{12}\right) \log_2\left(\frac{7}{12}\right) \approx 0.98
]
- آنتروپی برای افرادی که «انگیزه بالا» دارند:
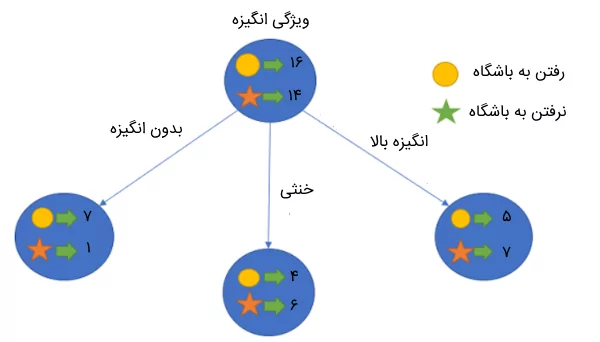
معیار Gini در درخت تصمیم
معیار جینی (Gini) یکی از روشهای مؤثر برای انتخاب مناسبترین ویژگی برای تقسیم دادهها در درخت تصمیم است و بهویژه برای دادههای گسسته کاربرد دارد. از آنجایی که در فرمول بهرهوری اطلاعات از لگاریتم استفاده شده است، بار محاسباتی آن بیشتر میشود. به همین دلیل، در ساخت درخت تصمیم، معیار جینی با فرمول زیر نسبت به IG ترجیح داده میشود:
[
\text{Gini Impurity} = 1 – \text{Gini}
]
فرمول بالا، میزان ناخالصی یک گره را نشان میدهد. مقدار Gini در این فرمول مجموع احتمال کلاسهای مختلف دادهها را در گره مشخص میکند و فرمول آن به صورت زیر است:
[
\text{Gini} = \sum_{i=1}^{n} p_i^2
]
بنابراین، میتوان فرمول ناخالصی جینی را به صورت زیر نوشت:
[
\text{Gini Impurity} = 1 – \sum_{i=1}^{n} p_i^2
]
هرچه مقدار ناخالصی جینی کمتر باشد، همگنی گره بیشتر است. به عبارتی، ناخالصی جینی یک گره خالص برابر با صفر است که در این صورت کلاس تمام دادههای گره مشابه هم هستند.
مثال برای درک بهتر معیار Gini
فرض کنید میخواهیم دانشآموزان یک کلاس را بر اساس دو ویژگی قد و وزن دستهبندی کنیم تا ببینیم آیا با این مشخصات میتوانند به عنوان بازیکن بسکتبال انتخاب شوند. از بین ۲۰ نفر از دانشآموزان، ۱۰ نفرشان میتوانند به عنوان بازیکن برگزیده شوند. حال، ویژگی قد و وزن مسئله را با استفاده از معیار جینی مورد بررسی قرار میدهیم تا مشخص کنیم کدام ویژگی بهترین تفکیک را ارائه میدهد و میتواند به عنوان گره ریشه در درخت تصمیم انتخاب شود.
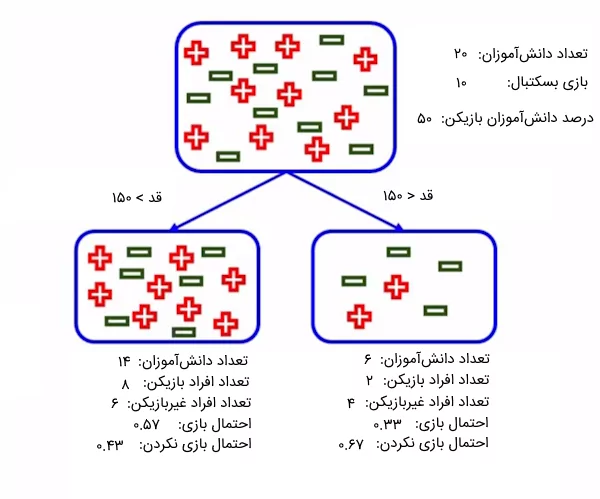
کاربرد معیار جینی در درخت تصمیم
ابتدا، دادهها را بر اساس ویژگی قد تفکیک میکنیم. طبق تصویری که در بالا ملاحظه میکنید، از میان ۶ نفر از دانشآموزانی که قدشان از ۱۵۰ سانتیمتر کوتاهتر است، ۲ نفر میتوانند به عنوان بازیکن بسکتبال انتخاب شوند. همچنین، از بین ۱۴ دانشآموزی که قدشان بالای ۱۵۰ سانتیمتر است، ۸ نفرشان را میتوان برای بازی برگزید.
حال، مقدار ناخالصی معیار جینی را برای گره سمت راست (افراد با قد کمتر از ۱۵۰ سانتیمتر) محاسبه میکنیم:
[
\text{Gini Impurity} = 1 – \left[(0.33) \times (0.33) + (0.67) \times (0.67)\right] = 0.44
]
سپس، مقدار ناخالصی معیار جینی را برای گره سمت چپ (افراد با قد بیشتر از ۱۵۰ سانتیمتر) محاسبه میکنیم:
[
\text{Gini Impurity} = 1 – \left[(0.57) \times (0.57) + (0.43) \times (0.43)\right] = 0.49
]
در نهایت، مجموع وزندار ناخالصیهای جینی محاسبه شده را بر اساس فرمول زیر به دست میآوریم:
[
\text{Weighted Gini Impurity} = \left(\frac{14}{20} \times 0.49\right) + \left(\frac{6}{20} \times 0.44\right) = 0.475
]
مثال دیگر برای معیار جینی
حال، با استفاده از معیار جینی، بررسی میکنیم که این ویژگی چقدر توانسته است اطلاعات مناسب درباره ناخالصی بودن گرهها به ما ارائه دهد. ابتدا، مقدار ناخالصی معیار جینی را برای گره سمت راست (افراد با وزن بیشتر از ۵۰ کیلوگرم) محاسبه میکنیم:
[
\text{Gini Impurity} = 1 – \left[(0.2) \times (0.2) + (0.8) \times (0.8)\right] = 0.32
]
سپس، مقدار ناخالصی معیار جینی را برای گره سمت چپ (افراد با وزن کمتر از ۵۰ کیلوگرم) محاسبه میکنیم:
[
\text{Gini Impurity} = 1 – \left[(0.8) \times (0.8) + (0.2) \times (0.2)\right] = 0.32
]
در نهایت، مجموع وزندار ناخالصیهای جینی محاسبه شده را بر اساس فرمول زیر به دست میآوریم:
[
\text{Weighted Gini Impurity} = \left(\frac{10}{20} \times 0.32\right) + \left(\frac{10}{20} \times 0.32\right) = 0.32
]
با این توضیحات، میتوانیم به درک بهتری از معیار جینی و کاربرد آن در الگوریتم درخت تصمیم برسیم. این معیار به ما کمک میکند تا بهترین ویژگیها را برای تقسیم دادهها شناسایی کنیم و به تصمیمگیریهای بهتری دست یابیم.
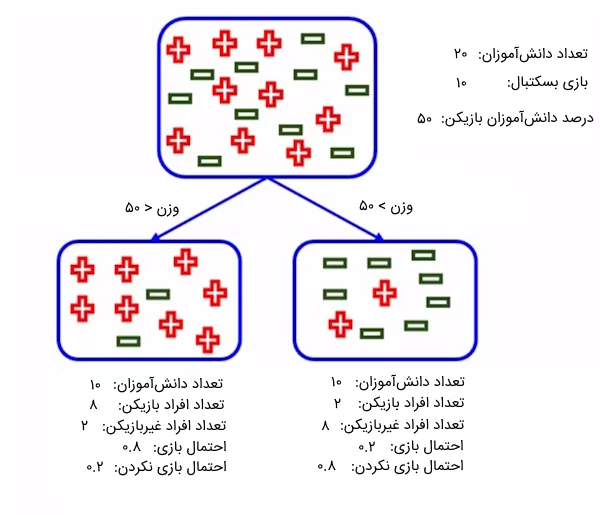
انتخاب ویژگی و توقف تقسیم درخت تصمیم
همانطور که از محاسبات مشخص است، ویژگی وزن با مقدار Gini برابر با ۰.۳۲ در مقایسه با ویژگی قد که مقدار Gini آن ۰.۴۷۵ است، بهتر توانسته دادهها را تقسیم کند و مقدار ناخالصی دادهها پس از تقسیم کاهش یافته است. بنابراین، میتوانیم ویژگی وزن را برای گره ریشه در درخت تصمیم انتخاب کنیم.
چه زمانی باید تقسیم گرهها را متوقف کنیم؟
با مطالعه بخشهای قبلی، ممکن است این سوال برای شما پیش آمده باشد که چه زمانی باید رشد درخت تصمیم را متوقف کنیم. در دنیای واقعی، معمولاً با مسائلی مواجه هستیم که دادههای آنها شامل ویژگیهای زیادی هستند. این امر میتواند منجر به رشد بیش از حد درخت و تعداد زیاد تقسیمات گرهها شود. ساخت چنین درختهای بزرگی زمانبر است و ممکن است به وضعیت بیش برازش (Overfitting) منجر شود، به طوری که الگوریتم ما بر روی مجموعه دادههای آموزشی دقت بالایی داشته باشد اما بر روی دادههای آزمایشی عملکرد ضعیفی از خود نشان دهد. برای بهبود عملکرد الگوریتم درخت تصمیم، میتوان از دو روش زیر استفاده کرد:
- تنظیم ابرپارامترهای درخت تصمیم
- هرس کردن درخت تصمیم
در ادامه به توضیح هر یک از این روشها میپردازیم
ابرپارامترهای الگوریتم درخت تصمیم
تنظیم ابرپارامترها میتواند به رفع مشکل بیش برازش و رشد بیش از حد درخت تصمیم کمک کند. یکی از این پارامترها، max_depth است که حداکثر عمق درخت تصمیم را تعیین میکند. هرچه مقدار max_depth بیشتر باشد، درخت پیچیدهتر و بزرگتر خواهد شد. اگر مقدار max_depth را افزایش دهیم، خطای زمان آموزش (Training Error) به طور طبیعی کاهش مییابد، اما ممکن است دقت الگوریتم بر روی دادههای تست به شدت کاهش یابد. بنابراین، باید با امتحان کردن مقادیر مختلف برای این پارامتر، عملکرد الگوریتم را بررسی کنیم و مقداری را انتخاب کنیم که نه باعث بیش برازش و نه باعث وضعیت برازش ناکافی (Underfitting) شود. برازش ناکافی زمانی رخ میدهد که الگوریتم عملکرد خوبی بر روی دادههای آموزشی نداشته باشد.
روش دیگری که میتوان برای بهبود عملکرد درخت تصمیم استفاده کرد، تنظیم حداقل تعداد نمونه برای هر تقسیم است. با استفاده از پارامتر min_samples_split میتوانیم حداقل تعداد نمونه را مشخص کنیم. به عنوان مثال، میتوانیم حداقل ۱۰ نمونه را برای رسیدن به یک تصمیم تعیین کنیم. این بدان معناست که اگر یک گره کمتر از ۱۰ نمونه داشته باشد، با استفاده از این پارامتر میتوانیم فرآیند تقسیم گره را متوقف کرده و آن را به یک گره نهایی (Leaf Node) تبدیل کنیم تا نتیجه نهایی الگوریتم مشخص شود.
علاوه بر این، دو ابرپارامتر دیگر نیز میتوانند در راستای بهبود عملکرد الگوریتم درخت تصمیم مؤثر باشند:
- min_samples_leaf: این ابرپارامتر حداقل تعداد نمونههای مورد نیاز برای قرار گرفتن در گره نهایی را مشخص میکند. هر چه مقدار این ابرپارامتر بیشتر باشد، احتمال رخداد بیش برازش افزایش مییابد.
- max_features: این ابرپارامتر به ما کمک میکند تا تصمیم بگیریم هنگام جستجو برای بهترین تقسیم، چند ویژگی را در نظر بگیریم.
با استفاده از این روشها و تنظیمات، میتوانیم عملکرد درخت تصمیم را بهبود بخشیم و از بروز مشکلاتی مانند بیش برازش جلوگیری کنیم.
هرس کردن در درخت تصمیم چیست؟
هرس کردن (Pruning) یکی از روشهای مؤثر برای جلوگیری از بروز وضعیت بیش برازش (Overfitting) در درختهای تصمیم است. این روش با حذف گرهها یا زیرگرههای کماهمیت به بهبود عملکرد درخت تصمیم کمک میکند و میتواند شاخههایی از درخت را که اهمیت بسیار پایینی دارند، حذف کند. دو روش اصلی برای هرس کردن درخت تصمیم وجود دارد:
- پیشهرس (Pre-pruning)
- پسهرس (Post-pruning)

در ادامه، به توضیح هر یک از این روشهای هرس کردن در درخت تصمیم میپردازیم.
پیشهرس در درخت تصمیم چیست؟
پیشهرس یکی از روشهای هرس کردن در درختهای تصمیم است که در آن ابرپارامترها قبل از فرایند آموزش تنظیم میشوند. این روش به منظور توقف زودهنگام الگوریتم استفاده میشود تا از رشد کامل درخت تصمیم جلوگیری کند. هدف از توقف زودهنگام، جلوگیری از ایجاد برگهایی با نمونههای کمتعداد است. در هر مرحله از تقسیم درخت، خطای اعتبارسنجی متقابل (Cross Validation Error) بررسی میشود. اگر مقدار این خطا تغییری نکند، رشد درخت متوقف میشود.
ابرپارامترهایی که میتوان برای توقف زودهنگام و جلوگیری از بروز بیش برازش تنظیم کرد، شامل موارد زیر هستند:
- max_depth: حداکثر عمق درخت تصمیم را مشخص میکند.
- min_samples_leaf: حداقل تعداد نمونه در برگهای درخت تصمیم را تعیین میکند.
- min_samples_split: حداقل تعداد نمونه در گره برای ایجاد یک تقسیم جدید را مشخص میکند.
این ابرپارامترها همچنین میتوانند برای تنظیم یک مدل کارآمد استفاده شوند. با این حال، باید احتیاط کرد زیرا توقف زودهنگام ممکن است منجر به برازش ناکافی (Underfitting) نیز شود.
پسهرس در درخت تصمیم چیست؟
برخلاف روش پیشهرس، در پسهرس به درخت تصمیم اجازه داده میشود تا به طور کامل رشد کند. پس از رسیدن به عمق کامل، به منظور جلوگیری از بروز بیش برازش، برخی از شاخههای درخت حذف میشوند.
در این روش، الگوریتم تقسیم دادهها را به زیرمجموعههای کوچکتر ادامه میدهد تا زمانی که زیرمجموعههای نهایی از نظر کلاس مشابه شوند. زیرمجموعه نهایی درخت تنها شامل چند نقطه داده خواهد بود و به درخت اجازه میدهد تا دادهها را به طور کامل یاد بگیرد. با این حال، ممکن است درخت تصمیم در زمان تست درباره یک داده جدید به درستی تصمیم نگیرد.
ابرپارامتری که میتوان برای پسهرس و جلوگیری از بروز بیش برازش تنظیم کرد، ccp_alpha نام دارد. ccp مخفف عبارت هرس کردن با پیچیدگی هزینه (Cost Complexity Pruning) است و میتواند به عنوان عاملی برای کنترل اندازه درخت استفاده شود. هر چه مقدار ابرپارامتر ccp_alpha بیشتر باشد، تعداد گرههای هرسشده نیز بیشتر خواهد شد.
با استفاده از این روشهای هرس کردن، میتوان عملکرد درخت تصمیم را بهبود بخشید و از بروز مشکلاتی مانند بیش برازش جلوگیری کرد.
ویژگیهای درخت تصمیم
الگوریتم درخت تصمیم برای حل مسائل مختلف، چندین فرضیه را در نظر میگیرد که به ساخت صحیح درخت و بهبود عملکرد آن کمک میکنند. در اینجا به برخی از فرضیههای رایج و نکات قابل توجه هنگام ایجاد درختهای تصمیم اشاره میکنیم:
تقسیم دوتایی گرهها: درختهای تصمیم معمولاً تقسیمهای دودویی انجام میدهند. این بدان معناست که هر گره بر اساس یک ویژگی یا شرط به دو زیرمجموعه تقسیم میشود. این فرض بر این مبنا است که هر تصمیم را میتوان به عنوان یک انتخاب دودویی (دو حالته) نشان داد.
تقسیمبندی بازگشتی: درخت تصمیم از فرایندی به نام تقسیمبندی بازگشتی استفاده میکند. در این فرایند، هر گره به زیرگرههای فرزند تقسیم میشود و این فرآیند تا زمانی ادامه مییابد که معیار توقف برآورده شود. این فرآیند فرض میکند که دادهها را میتوان به طور مؤثر به زیرمجموعههای کوچکتر تقسیم کرد.
مستقل بودن ویژگیها: درخت تصمیم معمولاً این فرض را در نظر میگیرد که ویژگیهایی که برای تقسیم گرهها استفاده میشوند، مستقل از هم هستند. در عمل، ممکن است این استقلال وجود نداشته باشد، اما حتی با وجود همبستگی بین ویژگیها، درخت تصمیم میتواند به عملکرد خوبی برسد.
همگن بودن دادهها در هر گره: درخت تصمیم تلاش میکند در هر گره زیرگروههای همگن ایجاد کند. به عبارتی، این مدل سعی دارد دادههایی را که از کلاس مشابهی هستند، در یک گره مجزا قرار دهد. این فرضیه میتواند به ایجاد مرزهای تصمیمگیری کمک کند.
رویکرد حریصانه بالا-به-پایین: درخت تصمیم بر پایه رویکرد حریصانه بالا-به-پایین ساخته میشود. بر اساس این رویکرد، تقسیم دادهها در گرهها برای به حداکثر رساندن مقدار معیار IG یا کاهش میزان آنتروپی انجام میشود. البته باید به این نکته اشاره کرد که چنین رویکردی تضمین نمیدهد همیشه بهینهترین درخت تصمیم ساخته شود.
ویژگیهای مقولهای و عددی: درخت تصمیم میتواند با هر دو نوع ویژگی مقولهای و عددی کار کند. با این حال، ممکن است برای هر نوع ویژگی نیاز به استراتژیهای تقسیمبندی متفاوتی باشد.
هرس کردن برای جلوگیری از بیش برازش: با وجود نویز در دادهها، درخت تصمیم مستعد بیش برازش میشود. این مدل برای مقابله با این شرایط، از هرس کردن و تعیین معیارهای توقف رشد درخت استفاده میکند.
معیارهای ناخالصی: درخت تصمیم از معیارهای ناخالصی مانند معیار جینی یا آنتروپی برای ارزیابی کیفیت تفکیک کلاسها توسط یک گره تقسیم استفاده میکند. انتخاب معیار ناخالصی میتواند بر ساختار درخت تأثیر بگذارد.
عدم وجود مقادیر نامشخص: درخت تصمیم فرض میکند که هیچ مقدار گمشدهای در مجموعه داده وجود ندارد یا مقادیر گمشده به درستی از طریق پر کردن داده با مقادیر مشخص مقداردهی شدهاند.
برابر بودن ویژگیها: درخت تصمیم ممکن است اهمیت همه ویژگیها را یکسان در نظر بگیرد. البته این مدل میتواند برای تأکید بر برخی ویژگیهای خاص از روش «مقیاسبندی ویژگی» یا «وزندهی» استفاده کند.
حساس بودن به دادههای پرت: درخت تصمیم نسبت به دادههای پرت حساس است و این مقادیر میتوانند بر عملکرد الگوریتم تأثیر منفی بگذارند. برای مدیریت مؤثر دادههای پرت، ممکن است نیاز به پیشپردازش داده باشد.
حساس بودن به حجم دادهها: درخت تصمیم نسبت به حجم داده حساس است. اگر حجم دادههای آموزشی کم باشد، ممکن است وضعیت بیش برازش اتفاق بیفتد و اگر حجم دادهها زیاد باشد، احتمال دارد که ساختار درخت تصمیم بسیار پیچیده و بزرگ شود. بنابراین، باید تعادلی بین حجم داده و عمق درخت برقرار کرد تا از مشکلات احتمالی جلوگیری شود.
مثال الگوریتم درخت تصمیم
حال که به این پرسش پاسخ دادیم که الگوریتم درخت تصمیم چیست و به اصطلاحات فنی این مدل یادگیری ماشین پرداختیم، در ادامه یک مثال ساده برای دستهبندی دادهها با درخت تصمیم ارائه میکنیم. فرض کنید اطلاعاتی از حیوانات مختلف در اختیار داریم و میخواهیم هر حیوانی را با استفاده از درخت تصمیم بر اساس ویژگیهایش شناسایی و طبقهبندی کنیم.
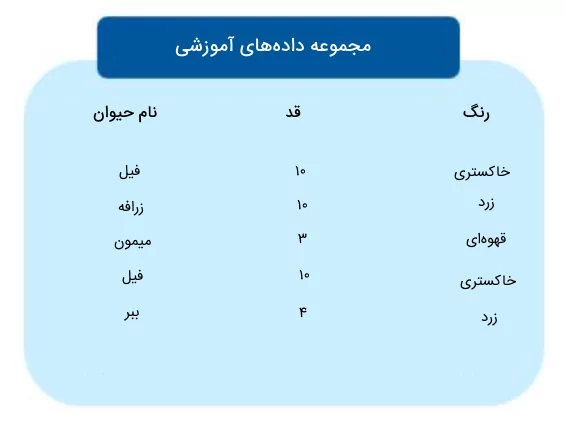
برای این منظور، باید مشخص کنیم کدام ویژگی باعث میشود تقسیم دادهها در گروههای مختلف به نحوی انجام شود که بیشترین اطلاعات را به دست آوریم و میزان ناخالصی حاصل شده در گرههای فرزند کمتر شود. برای این مسئله میتوان از IG یا Gini برای تعیین ویژگی مناسب استفاده کرد. به عنوان مثال، شروط زیر میتوانند به عنوان عامل تقسیم دادهها لحاظ شوند:

اگر از معیار IG برای انتخاب ویژگی رنگ برای گره ریشه استفاده کنیم، میبینیم که بیشترین اطلاعات را ارائه میدهد و در مقایسه با سایر ویژگیها، ناخالصی دادهها را پس از تقسیم، کمتر میکند.
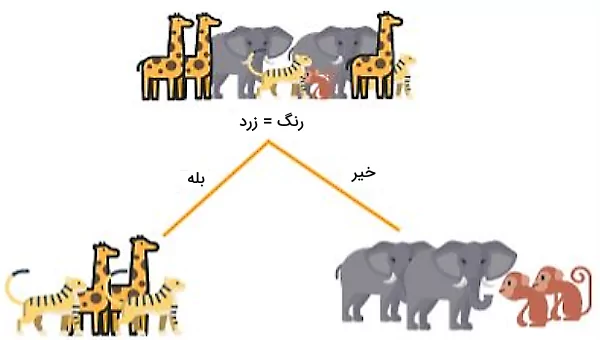
پس از تقسیم دادهها بر اساس رنگ حیوانات، مقدار آنتروپی به طور قابل توجهی کاهش مییابد. با این حال، برای رسیدن به مقدار آنتروپی صفر، همچنان نیاز است دادههای گرههای فرزند را در هر دو شاخه تقسیم کنیم. این بار، هر دو گره را بر اساس ویژگی قد تقسیم و از شرایط قد بلندتر و کوتاهتر از ۱۰ سانتیمتر به عنوان معیار استفاده میکنیم.
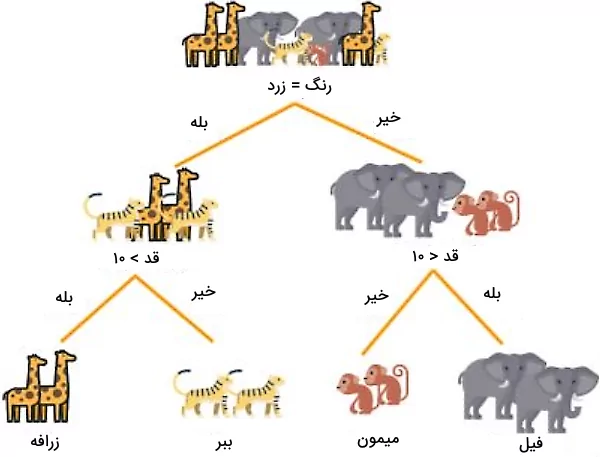
همانطور که مشاهده میکنید، با تقسیم دادهها بر اساس ویژگی قد، در گرههای جدید، دادهها به درستی تفکیک شدهاند و مقدار آنتروپی در هر یک از گرههای ایجاد شده برابر با ۰ است. بدین ترتیب، الگوریتم درخت تصمیم متوقف میشود و گرههای نهایی ساخته شده به عنوان گره برگ در نظر گرفته میشوند.
مزایا و معایب الگوریتم درخت تصمیم
پس از توضیح درباره درخت تصمیم و عملکرد آن، به نقاط قوت و ضعف این الگوریتم میپردازیم. با توجه به مزایای آشکار، درخت تصمیم به طور گسترده در مسائل مختلف یادگیری ماشین کاربرد دارد. مهمترین مزایای این الگوریتم عبارتند از:
1. قابل تفسیر و تجسم آسان: درخت تصمیم به گونهای طراحی شده است که تجزیه و تحلیل آن آسان است. قوانین تصمیمگیری در هر گره به وضوح نمایش داده میشوند.
2. قابلیت شناسایی الگوهای غیرخطی: این الگوریتم توانایی شناسایی و تحلیل الگوهای غیرخطی موجود در دادهها را دارد.
3. نیاز کم به پیشپردازش دادهها: درختهای تصمیم معمولاً به حداقل پیشپردازش دادهها نیاز دارند، به ویژه در مقایسه با دیگر الگوریتمهای یادگیری ماشین.
4. استفاده در مهندسی ویژگیها: این الگوریتم میتواند برای پیشبینی مقادیر گمشده یا انتخاب ویژگیهای کلیدی به کار رود.
5. عدم نیاز به فرضیات خاص: درخت تصمیم به دلیل ذات غیرپارامتری خود، نیازی به فرضیات خاصی درباره توزیع دادهها ندارد.
اما الگوریتم درخت تصمیم برخی معایب نیز دارد که به آنها اشاره میشود:
1. حساسیت به نویز: درختهای تصمیم به دادههای پر از نویز حساساند و این مسئله میتواند منجر به بیشبرازش شود.
2. عدم ثبات با تغییرات کوچک: تغییرات جزئی در دادهها میتواند تأثیر زیادی بر روی ساختار درخت تصمیم بگذارد.
3. سوگیری با دادههای نامتوازن: این الگوریتم ممکن است نسبت به دادههای نامتوازن سوگیری کند؛ بنابراین، قبل از استفاده، بهتر است دادهها متوازن شوند.
کاربردهای درخت تصمیم
درختهای تصمیم میتوانند برای مسائل طبقهبندی و رگرسیون به کار گرفته شوند و این ویژگی آنها را به ابزاری انعطافپذیر برای حل مسائل مختلف تبدیل میکند. برخی از کاربردهای رایج درخت تصمیم شامل موارد زیر است:
1. تصمیمگیری روزمره: درختهای تصمیم به طور ضمنی در زندگی روزمره ما حضور دارند. برای مثال، هنگام انتخاب لباس به شرایط آب و هوا توجه میکنیم.
2. مراقبتهای بهداشتی: در حوزه پزشکی، درختهای تصمیم میتوانند به پزشکان در تشخیص بیماریها کمک کنند.
3. تحلیلهای مالی: این الگوریتم در قیمتگذاری معاملات و توسعه استراتژیهای مالی به کار میرود.
4. مدیریت ارتباط با مشتری: شرکتها از درختهای تصمیم برای پیشبینی رفتار مشتریان بهره میبرند و استراتژیهای مناسب را براساس آن تنظیم میکنند.
5. کنترل کیفیت محصولات: در زمینه تولید، میتوان از درختهای تصمیم برای ارزیابی احتمال عدم موفقیت یک محصول در تست کیفیت استفاده کرد.
6. تشخیص کلاهبرداری: این الگوریتم میتواند در شناسایی فعالیتهای مشکوک در تراکنشها بسیار مؤثر باشد.
7. سیستمهای توصیهگر: بسیاری از پلتفرمهای آنلاین برای ارائه پیشنهادات مناسب از درختهای تصمیم استفاده میکنند.
با توجه به مزایا و معایب الگوریتم درخت تصمیم و کاربردهای گسترده آن، این الگوریتم به عنوان یکی از ابزارهای کلیدی در یادگیری ماشین شناخته میشود.
درخت تصمیم در زبان پایتون
در این مقاله به بررسی جامع مفهوم درخت تصمیم و معیارهای عملکرد آن پرداختهایم. در این بخش، روش استفاده از این الگوریتم برای طبقهبندی دادهها را بررسی خواهیم کرد تا خوانندگان بتوانند با شیوه پیادهسازی درخت تصمیم در زبان برنامهنویسی پایتون آشنا شوند. پایتون به عنوان یکی از بهترین زبانهای برنامهنویسی برای یادگیری ماشین شناخته میشود و دارای کتابخانههای جامع هوش مصنوعی است.
برای پیادهسازی درخت تصمیم، میتوان از مجموعه دادههای آموزشی مختلف استفاده کرد. در این مقاله، از دادههای آموزشی موجود در سایت Kaggle بهره میبریم که شامل اطلاعات پزشکی بیمارانی است که هدف ما تشخیص وجود یا عدم وجود بیماری دیابت در آنها بر اساس ویژگیهای مختلف میباشد. برای بارگذاری کتابخانههای لازم برای پیادهسازی درخت تصمیم، از کد زیر استفاده میکنیم:
# Load libraries
import pandas as pd
from sklearn.tree import DecisionTreeClassifier # Import Decision Tree Classifier
from sklearn.model_selection import train_test_split # Import train_test_split function
from sklearn import metrics #Import scikit-learn metrics module for accuracy calculation
سپس، دادههای مسئله را بعد از دانلود کردن بر روی سیستم، در برنامه بارگذاری میکنیم و نام ویژگیها را تغییر میدهیم
col_names = ['pregnant', 'glucose', 'bp', 'skin', 'insulin', 'bmi', 'pedigree', 'age', 'label']
# load dataset
pima = pd.read_csv("diabetes.csv", header=0, names=col_names)
برای نمایش چندین سطر از دادهها، میتوانیم از کد زیر استفاده کنیم:
pima.head()
pima.head()
خروجی دستور بالا را در ادامه ملاحظه میکنید:
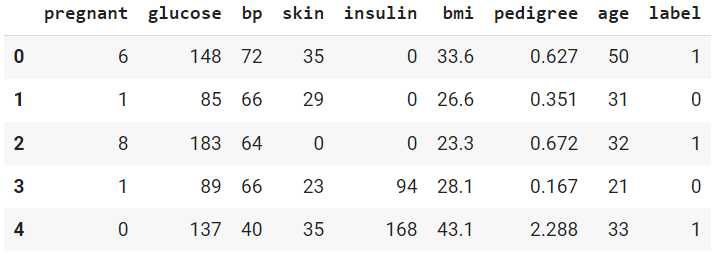
پس از نمایش دادهها، با استفاده از کد زیر، ویژگیها را از مقادیر هدف جدا میکنیم تا مشخصات ورودی مدل و مقادیر هدف تعیین شوند:
#split dataset in features and target variable
feature_cols = ['pregnant', 'insulin', 'bmi', 'age','glucose','bp','pedigree']
X = pima[feature_cols] # Features
y = pima.label # Target variable
سپس، با استفاده از کد زیر، دادههای آموزشی را از دادههای تست جدا میکنیم:
# Split dataset into training set and test set
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1) # 70% training and 30% test
برای آموزش درخت تصمیم و آزمایش آن، کد زیر را به کار میبریم:
# Create Decision Tree classifer object
clf = DecisionTreeClassifier()
# Train Decision Tree Classifer
clf = clf.fit(X_train,y_train)
#Predict the response for test dataset
y_pred = clf.predict(X_test)
برای ارزیابی عملکرد مدل درخت تصمیم، از کد زیر استفاده میکنیم:
# Model Accuracy, how often is the classifier correct?
print("Accuracy:",metrics.accuracy_score(y_test, y_pred))
خروجی کد بالا دقت مدل را نشان میدهد.
Accuracy: 0.6753246753246753
همچنین میتوانید درخت نهایی را با استفاده از کد زیر به نمایش درآورید:
import six
import sys
sys.modules['sklearn.externals.six'] = six
from sklearn.tree import export_graphviz
from sklearn.externals.six import StringIO
from IPython.display import Image
import pydotplus
dot_data = StringIO()
export_graphviz(clf, out_file=dot_data,
filled=True, rounded=True,
special_characters=True,feature_names = feature_cols,class_names=['0','1'])
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
graph.write_png('diabetes.png')
Image(graph.create_png())
با اجرای این کد، درخت تصمیم ساخته شده را مشاهده خواهید کرد
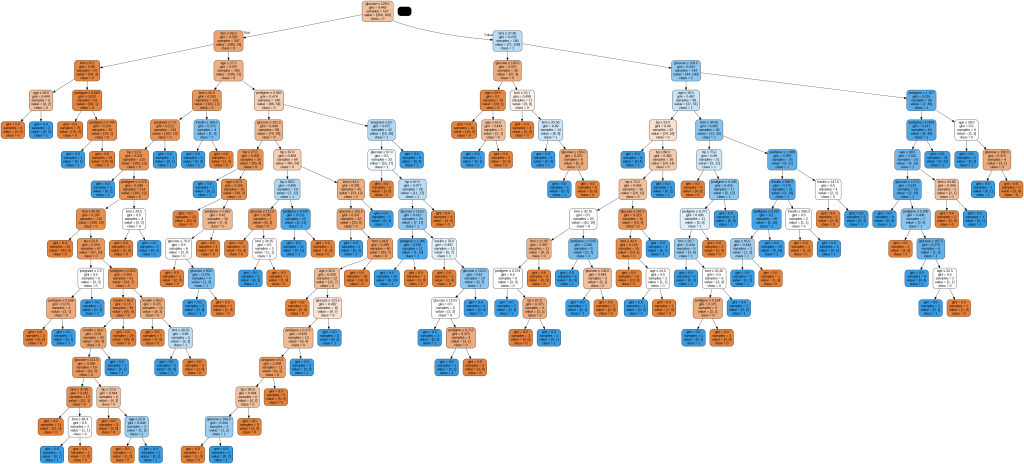
همانطور که در تصویربالامشاهده میشود، درخت ایجاد شده ممکن است بسیار بزرگ و پیچیده باشد. برای کاهش پیچیدگی درخت، میتوانیم از روش هرس استفاده کنیم و مثلاً تعیین کنیم که تعداد سطوح درخت از سه بیشتر نشود. به این منظور، از کد زیر بهره میبریم:
# Create Decision Tree classifer object
clf = DecisionTreeClassifier(criterion="entropy", max_depth=3)
# Train Decision Tree Classifer
clf = clf.fit(X_train,y_train)
#Predict the response for test dataset
y_pred = clf.predict(X_test)
# Model Accuracy, how often is the classifier correct?
print("Accuracy:",metrics.accuracy_score(y_test, y_pred))
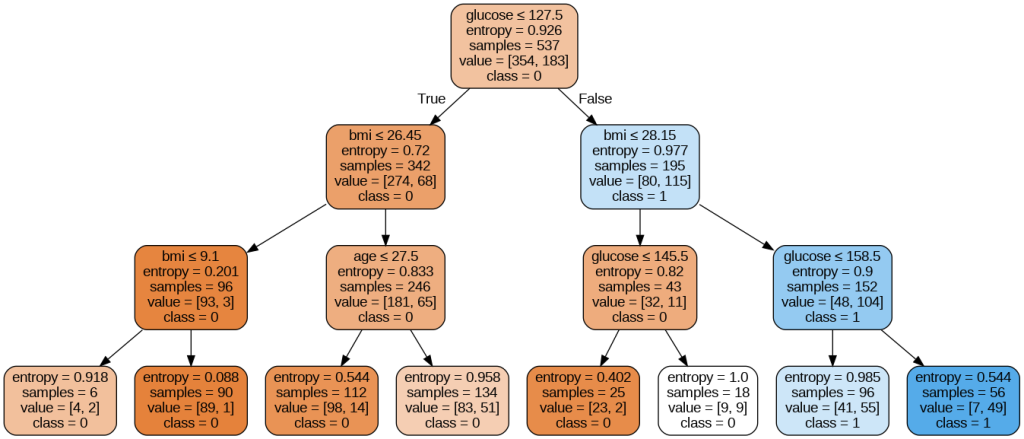
اجرای این کد موجب افزایش دقت مدل میشود. حال میتوانید با استفاده از کد زیر، ساختار درخت تصمیم را پس از هرس کردن به نمایش درآورید:
from six import StringIO
from IPython.display import Image
from sklearn.tree import export_graphviz
import pydotplus
dot_data = StringIO()
export_graphviz(clf, out_file=dot_data,
filled=True, rounded=True,
special_characters=True, feature_names = feature_cols,class_names=['0','1'])
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
graph.write_png('diabetes.png')
Image(graph.create_png())
خروجی قطعه کد بالا را در ادامه ملاحظه میکنید:
console.log( 'Code is Poetry' );
پس از آشنایی با نحوه پیادهسازی یک الگوریتم ساده درخت تصمیم و پاسخ به این پرسش که درخت تصمیم چیست، برای تقویت مهارتهای خود میتوانید به پیادهسازی مثالهای بیشتر پرداخته و با تنظیم ابرپارامترها و استفاده از شیوههای هرس، نتایج مدلها را مقایسه کنید. همچنین، میتوانید به مطالعه دیگر روشها و مدلهای یادگیری ماشین ادامه دهید تا مهارتهای خود را در این زمینه افزایش دهید. برای یادگیری بیشتر، میتوانید از دورههای آموزشی فرادرس استفاده کنید که در ادامه به آنها اشاره شده است:
- فیلم آموزش تجزیه و تحلیل و آمادهسازی دادهها با پایتون
- فیلم آموزش ریاضی برای یادگیری ماشین + پیادهسازی در پایتون
- فیلم آموزش کتابخانه scikit-learn در پایتون – الگوریتمهای یادگیری ماشین
- فیلم آموزش یادگیری ماشین و پیادهسازی در پایتون – بخش اول
نتیجهگیری
الگوریتم درخت تصمیم یکی از ابزارهای قدرتمند و محبوب در حوزه یادگیری ماشین است که به دلیل سادگی در تفسیر و قابلیتهای بالای آن در حل مسائل مختلف، مورد توجه قرار گرفته است. این الگوریتم با استفاده از ساختار درختی، دادهها را بر اساس ویژگیهای مختلف تقسیمبندی میکند و به ما این امکان را میدهد که تصمیمات بهینهتری بگیریم.
با توجه به مزایا، معایب و کاربردهای گسترده الگوریتم درخت تصمیم، میتوان گفت که این الگوریتم یکی از ابزارهای کلیدی در یادگیری ماشین است. با استفاده صحیح از این الگوریتم و تنظیم مناسب ابرپارامترها، میتوان به نتایج بهینه و قابل اعتمادی در تحلیل دادهها و تصمیمگیریهای هوشمند دست یافت. در نهایت، درخت تصمیم به عنوان یک مدل یادگیری ماشین، به ما کمک میکند تا با استفاده از دادههای موجود، تصمیمات بهتری اتخاذ کنیم و به درک عمیقتری از الگوهای موجود در دادهها برسیم.

