

مهندسی ویژگی چیست؟ – Feature Engineering به زبان ساده
در دنیای یادگیری ماشین، دادهها نقش حیاتی دارند. اما دادهها همیشه بهطور مستقیم قابل استفاده نیستند. اغلب، دادهها نیاز به پاکسازی و پیشپردازش دارند تا برای مدلهای یادگیری ماشین آماده شوند. در این فرایند، «مهندسی ویژگی» یا Feature Engineering وارد عمل میشود. مهندسی ویژگی یکی از مهمترین گامها در ساخت مدلهای موفق یادگیری ماشین است و میتواند تفاوت زیادی در دقت و کارایی مدلها ایجاد کند.
مهندسی ویژگی چیست؟
مهندسی ویژگی به فرایند تبدیل دادههای خام به ویژگیهای معنادار و قابل استفاده برای مدلهای یادگیری ماشین گفته میشود. این فرایند شامل انتخاب، اصلاح، یا ساخت ویژگیهای جدید است که مدل یادگیری ماشین میتواند بهطور مؤثر از آنها برای انجام پیشبینیها و تحلیلها استفاده کند.
چرا مهندسی ویژگی اهمیت دارد؟
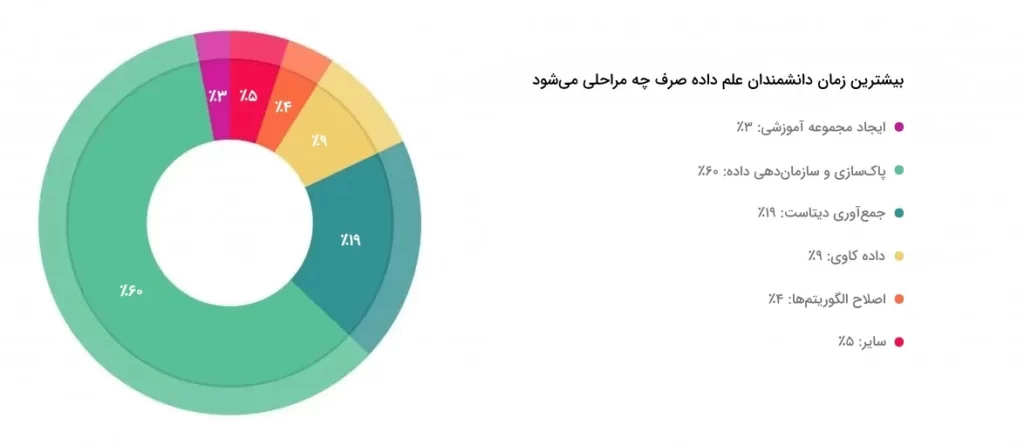
یکی از مراحل کلیدی در پروژههای یادگیری ماشین، پردازش دادهها است که اغلب زمان زیادی را به خود اختصاص میدهد. طبق نتایج نظرسنجی انجامشده توسط نشریه «فوربز» (Forbes)، حدود 80% از زمان متخصصان علم داده به پاکسازی و پیشپردازش دادههای خام اختصاص دارد. این آمار نشان میدهد که یکی از وظایف اصلی دانشمندان داده، پردازش دادهها و آمادهسازی آنها برای مدلهای یادگیری ماشین است. در این میان، مهندسی ویژگی نقشی حیاتی در آمادهسازی دادهها برای آموزش مدلهای یادگیری ماشین ایفا میکند.
دادههای خام و چالشهای آنها
دادههای خام که معمولاً از منابع مختلفی همچون وبسایتها، نظرسنجیها یا نقد و بررسیها جمعآوری میشوند، بهطور معمول حاوی مشکلاتی همچون مقادیر گمشده، ورودیهای نادرست و نمونههای پرت (Outliers) هستند. این دادهها معمولاً بهصورت غیرساختاری و بینظم هستند، که استفاده از آنها بهطور مستقیم در مدلهای یادگیری ماشین بدون هیچگونه پردازش، نمیتواند نتایج مطلوب و دقیقی بهدست دهد.
نقش مهندسی ویژگی در بهبود عملکرد مدل
مهندسی ویژگی فرآیندی است که بهطور مؤثر دادههای خام را پردازش کرده و ویژگیهای معنادار و قابل استفاده برای مدلهای یادگیری ماشین استخراج میکند. این کار شامل اصلاح دادهها، انتخاب ویژگیهای مهم و حذف ویژگیهای بیارزش است. به این ترتیب، مهندسی ویژگی به مرتبسازی و ساخت دادههای مناسب برای آموزش مدلهای یادگیری ماشین کمک میکند و باعث بهبود دقت و کارایی مدلها میشود.
معرفی انواع تکنیکهای مهندسی ویژگی
پس از آشنایی با مفهوم مهندسی ویژگی، حالا زمان آن رسیده است که با انواع تکنیکهای مهندسی ویژگی و نحوه پیادهسازی آنها آشنا شویم. در این بخش، ما از زبان برنامهنویسی پایتون و دو کتابخانه محبوب Pandas و Numpy برای اجرای این تکنیکها استفاده میکنیم. ابتدا کتابخانه Pandas را با دستور زیر در محیط خط فرمان (Command Line) نصب میکنیم:
pip install pandas
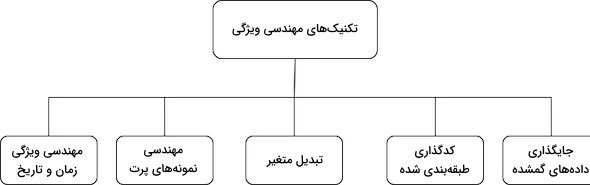
حالا که ابزارهای مورد نیاز برای پردازش دادهها را در اختیار داریم، میتوانیم به معرفی و بررسی تکنیکهای رایج مهندسی ویژگی بپردازیم. این تکنیکها بهطور کلی به پنج گروه اصلی تقسیم میشوند که در ادامه به توضیح هرکدام میپردازیم:
1. جایگذاری دادههای گمشده (Missing Data Imputation)
در بسیاری از دادهها، مقادیر گمشده وجود دارند که باید بهدرستی جایگزین شوند. برای جایگذاری دادههای گمشده از تکنیکهایی مانند میانگینگیری، میانه یا مد استفاده میشود. انتخاب روش مناسب بستگی به نوع داده و مدل مورد استفاده دارد.
2. کدگذاری طبقهبندیشده (Categorical Encoding)
دادههای طبقهبندیشده، مانند اطلاعات متنی (مثلاً جنسیت یا دستهبندیها)، باید به دادههای عددی تبدیل شوند تا مدلهای یادگیری ماشین بتوانند از آنها استفاده کنند. از تکنیکهایی مانند کدگذاری یکداغ (One-hot Encoding) یا کدگذاری برچسبی (Label Encoding) برای این منظور استفاده میشود.
3. تبدیل متغیرها (Variable Transformation)
تبدیل متغیرها به ویژگیهای جدید که اطلاعات بهتری ارائه دهند، یکی از تکنیکهای مهم در مهندسی ویژگی است. این کار میتواند شامل انجام عملیات ریاضی روی ویژگیهای موجود، مانند لوگگرفتن یا ریشهگیری متغیرها باشد.
4. مهندسی نمونههای پرت (Outlier Engineering)
نمونههای پرت یا Outliers، دادههایی هستند که بهطور قابل توجهی از سایر دادهها متفاوت هستند. حذف یا اصلاح این دادهها میتواند به بهبود عملکرد مدل کمک کند. تکنیکهایی مانند Hampel filter یا Z-score برای شناسایی و حذف نمونههای پرت بهکار میروند.
5. مهندسی ویژگی زمان و تاریخ (Time & Date Feature Engineering)
دادههای زمانی (مانند تاریخ و ساعت) اغلب بهصورت خام و بیساختار در دسترس هستند. با استفاده از تکنیکهای مهندسی ویژگی، میتوان ویژگیهایی مانند روز هفته، ماه، فصل، و تعطیلات را استخراج کرد. این ویژگیها میتوانند در مدلهای پیشبینی برای بهبود دقت نتایج مؤثر باشند.
مزایای مهندسی ویژگی چیست؟
پس از اینکه با مفهوم مهندسی ویژگی و نحوه پیادهسازی آن آشنا شدیم، حالا به بررسی مزایای این فرایند پرداخته و توضیح خواهیم داد که چرا مهندسی ویژگی در یادگیری ماشین و تحلیل دادهها اهمیت دارد. برخی از مزایای کلیدی مهندسی ویژگی عبارتند از:
1. بهبود کارایی و اثربخشی مدل
یکی از بزرگترین مزایای مهندسی ویژگی، افزایش کارایی و اثربخشی مدلهای یادگیری ماشین است. با پردازش و انتخاب ویژگیهای مناسب، مدلها میتوانند بهتر از دادهها یاد بگیرند و پیشبینیهای دقیقتری ارائه دهند.
2. برازش بهتر الگوریتمها به دادهها
مهندسی ویژگی کمک میکند تا الگوریتمهای یادگیری ماشین بهراحتی جهت حرکت دادهها را یاد بگیرند و بر آنها برازش (fit) شوند. این به مدلها اجازه میدهد که ساختارهای پیچیدهتر و دقیقتری را از دادهها استخراج کنند.
3. سادهسازی شناسایی الگوها
این فرآیند همچنین باعث سادهتر شدن شناسایی الگوهای موجود در دادهها میشود. وقتی دادهها بهصورت مناسب پردازش و مرتب میشوند، الگوریتمها قادرند بهراحتی و با دقت بیشتری الگوهای مخفی در دادهها را شناسایی کنند.
4. افزایش انعطافپذیری ویژگیها
مهندسی ویژگی به شما این امکان را میدهد که ویژگیها را بهطور مؤثر اصلاح کرده و آنها را با نیازهای مدل تطبیق دهید. این ویژگی باعث میشود که مدلها انعطافپذیرتر و دقیقتر در مواجهه با دادههای مختلف عمل کنند.

ابزارهای مهندسی ویژگی چیست؟
در این بخش از مقاله، پس از آشنایی با مفهوم مهندسی ویژگی و نحوه پردازش دادهها با استفاده از زبان برنامهنویسی پایتون، به معرفی ابزارهایی میپردازیم که به خودکارسازی این فرایند کمک میکنند. این ابزارها توانایی تولید حجم زیادی از ویژگیها را در مسائل مختلف دارند و بهویژه برای تسهیل فرایندهای پیچیده در دادهکاوی کاربرد دارند. در ادامه، چند ابزار پرکاربرد در این حوزه را بررسی میکنیم:
1. FeatureTools
FeatureTools یکی از فریمورکهای رایج برای خودکارسازی فرایند مهندسی ویژگی است. این ابزار بهویژه در تبدیل دادههای زمانی و رابطهای به ماتریسهای متناظر برای الگوریتمهای یادگیری ماشین کاربرد دارد. علاوه بر این، FeatureTools با ابزارهای دیگری مانند کتابخانه Pandas یکپارچه است و این یکپارچگی باعث افزایش سرعت ایجاد ویژگیها و بهبود عملکرد مدلها میشود.
2. AutoFeat
AutoFeat ابزاری است که فرایند انتخاب ویژگی و مهندسی ویژگی را در مدلهای خطی تسهیل میکند. این ابزار بهویژه در تغییر واحد متغیرهای ورودی برای جلوگیری از ناهماهنگی دادهها مفید است. این ویژگی باعث میشود که فرایند پیشپردازش دادهها سریعتر و با دقت بیشتری انجام شود.
3. TsFresh
TsFresh یک کتابخانه پایتون است که بهویژه برای کار با دادههای سری زمانی طراحی شده است. این ابزار میتواند حجم زیادی از ویژگیهای سری زمانی را محاسبه و ایجاد کند. همچنین TsFresh دارای توابعی است که با استفاده از آنها میتوان شدت تاثیرگذاری ویژگیها را در مسائل رگرسیون و طبقهبندی ارزیابی کرد.
4. OneBM
OneBM ابزاری است که در تعامل مستقیم با جداول پایگاه داده قرار دارد. این ابزار قادر است جداول را ادغام کرده و نوع دادهها را شناسایی کند. همچنین روشهای پردازشی معینی را برای انواع مختلف دادهها بهکار میگیرد، که این ویژگیها باعث تسهیل در پردازش دادههای پیچیده میشود.
5. ExploreKit
ExploreKit ابزاری است که الهامگرفته از ایده ایجاد ویژگیهای پیچیده از اطلاعات پایه و اولیه است. این ابزار ابتدا الگوهای رایج موجود را شناسایی کرده و سپس در ویژگیها تغییر ایجاد میکند. بهجای گزینش از میان تمامی ویژگیها، که ممکن است هزینهبر باشد، ExploreKit ابتدا ویژگیها را ردهبندی کرده و سپس تنها ویژگیهای منتخب را بهکار میبرد.

راه سریع برای یادگیری دادهکاوی و یادگیری ماشین
اگر بهدنبال یادگیری سریع و اصولی دادهکاوی و یادگیری ماشین هستید، تمرکز بر مهندسی ویژگی میتواند نقطه شروع بسیار خوبی باشد. مهندسی ویژگی شامل مجموعهای از تکنیکها برای انتخاب، استخراج و ساخت ویژگیهای مناسب از دادههای خام است. تسلط بر این مهارت به شما این امکان را میدهد که دادههایی با کیفیت بالا برای مدلهای یادگیری ماشین خود آماده کنید و عملکرد مدلها را بهبود بخشید.
با این حال، دادهکاوی تنها به مهندسی ویژگی محدود نمیشود و شامل موضوعات بسیار گستردهتری است. پس از آمادهسازی دادهها و انجام مهندسی ویژگی، گام بعدی انتخاب و آموزش مدلهای یادگیری ماشین است. این مدلها ممکن است شامل الگوریتمهای رگرسیون، طبقهبندی، خوشهبندی و دیگر روشهای پیشبینی باشند که در تحلیل و پردازش دادههای بزرگ به کار میروند.
برای یادگیری سریعتر و اصولی، توصیه میشود که در ابتدا با مفاهیم پیشپردازش دادهها و مهندسی ویژگی شروع کنید و سپس به سراغ انتخاب مدلها و آموزش آنها بروید. در کنار اینها، مطالعه الگوریتمهای مختلف یادگیری ماشین و آزمایش آنها در پروژههای عملی کمک میکند تا دانش شما گسترش یابد.
یادگیری دادهکاوی و یادگیری ماشین ممکن است در ابتدا پیچیده بهنظر برسد، اما با تمرکز بر موضوعاتی مانند مهندسی ویژگی، و گام به گام پیشبردن مسیر یادگیری، میتوانید بهسرعت به تسلط بر این حوزه دست یابید. این مهارتها به شما کمک میکنند تا در پروژههای واقعی دادهکاوی و یادگیری ماشین موفق باشید.